首先,虽然纽约是目前的重灾区,但生活其中也就那样。现在已经对各类甩锅与追责没了一丝兴趣,只是些憋在家里郁闷情绪的释放途径而已,这对个人认知失调的恢复是有用的,对疫情控制毫无价值。取笑、傲慢、愤怒、仇恨、谄媚、悲痛…你不能用人际交往中的情绪去跟病毒讨价还价,病毒不会因为个人、市场或群体情绪的波动而变弱或变强,那种一切尽在掌握的虚拟掌控感只是过去两百年科技发展的一个有毒的副产品,这个时间借鸡下蛋的行为值得钉在人类发展的耻辱柱上促人反思。瘟疫流行是一种短板效应,任何的疏忽与大意都会让前面的努力白费,那种觉着自己暂时没事就真没事的人值得拥有一次自然选择的机会。
我比较关心病毒传播中社区差异,而这个问题平时由于较大的人口流动几乎不能研究。但居家令出了后就不一样了,在居家令的背景下,你当然还是无法保证所有人不流动,但风险意识会让多数人留在家里。在纽约市,人口流动减弱后我们就可以看到社区间交流的程度了,纽约是存在明显社区隔离的,特别是种族间隔离,不同社区间相隔也就是一条街,但区间可能几乎没有交流。那么,理论上纽约的社区间新冠病毒也会存在斑块化,相邻街区也许人口密度接近,但因为社交隔离病毒的传播力也应该有明显差异。那么如何找人口基数差不多的街区呢?这里我用邮编来替代,因为过去设计邮编就是按人数来的,不过时过境迁现在邮编已经不能反映当前居住人口了,但似乎也没有别的方法(其实有,通信商与大型互联网公司可以做到,但我搞不到这些数据)。好,我们来攒一下数据。
library(tidycensus)
library(tidyverse)## ── Attaching packages ────────────────────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.0 ✓ purrr 0.3.3
## ✓ tibble 3.0.0 ✓ dplyr 0.8.5
## ✓ tidyr 1.0.2 ✓ stringr 1.4.0
## ✓ readr 1.3.1 ✓ forcats 0.5.0## ── Conflicts ───────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()census_api_key("USE YOUR KEY")## To install your API key for use in future sessions, run this function with `install = TRUE`.# 纽约市各邮编确诊数据
covid19nyc <- read.csv('https://raw.githubusercontent.com/nychealth/coronavirus-data/master/tests-by-zcta.csv')
# 提取2018年人口普查数据
zip <- get_acs(geography = "zcta",
variables = c(medincome = "B19013_001",
population = "B01003_001",
asian = "B02001_005",
black="B02001_003",
white="B02001_002"),
year = 2018)## Getting data from the 2014-2018 5-year ACSzipnyc <- merge(covid19nyc,zip,by.x = 'MODZCTA',by.y='GEOID')
# reshape
zipnyc2 <- tidyr::pivot_wider(zipnyc[,-c(3,4,5,8)],names_from = variable, values_from = estimate) %>%
mutate(rate=Positive/population,arate=asian/population,brate=black/population,wrate=white/population)这里我收集了纽约市不同邮编的发病人数,除以2018年人口调查的人数就是发病率。然后我计算了亚裔、非裔与白人的人口比例。下面我们就先看一下图。
# 社区发病率与收入
ggplot(zipnyc2,mapping = aes(medincome,rate))+geom_point()+geom_smooth()## `geom_smooth()` using method = 'loess' and formula 'y ~ x'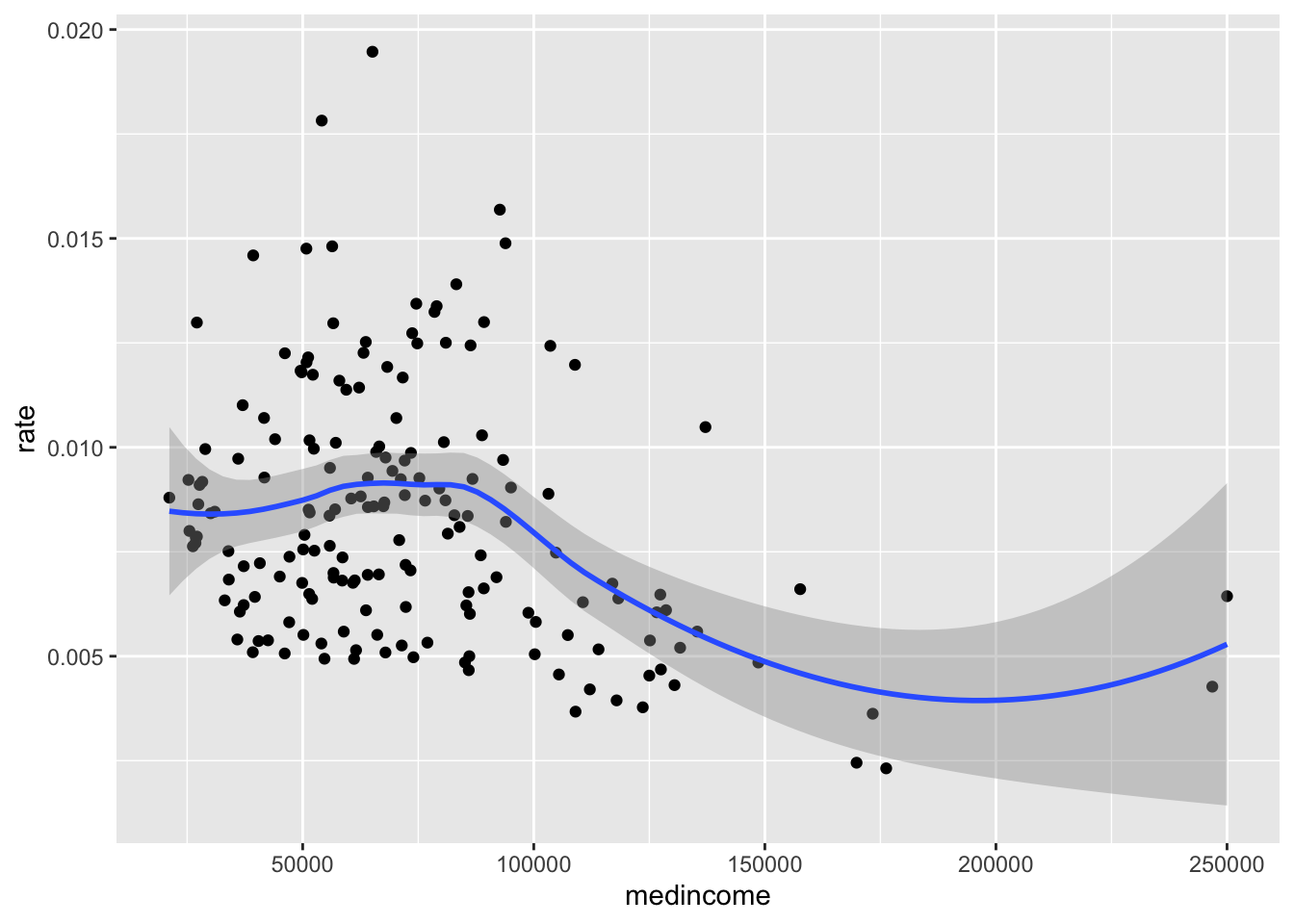
# 社区发病率与亚裔比例
ggplot(zipnyc2,mapping = aes(arate,rate))+geom_point()+geom_smooth()## `geom_smooth()` using method = 'loess' and formula 'y ~ x'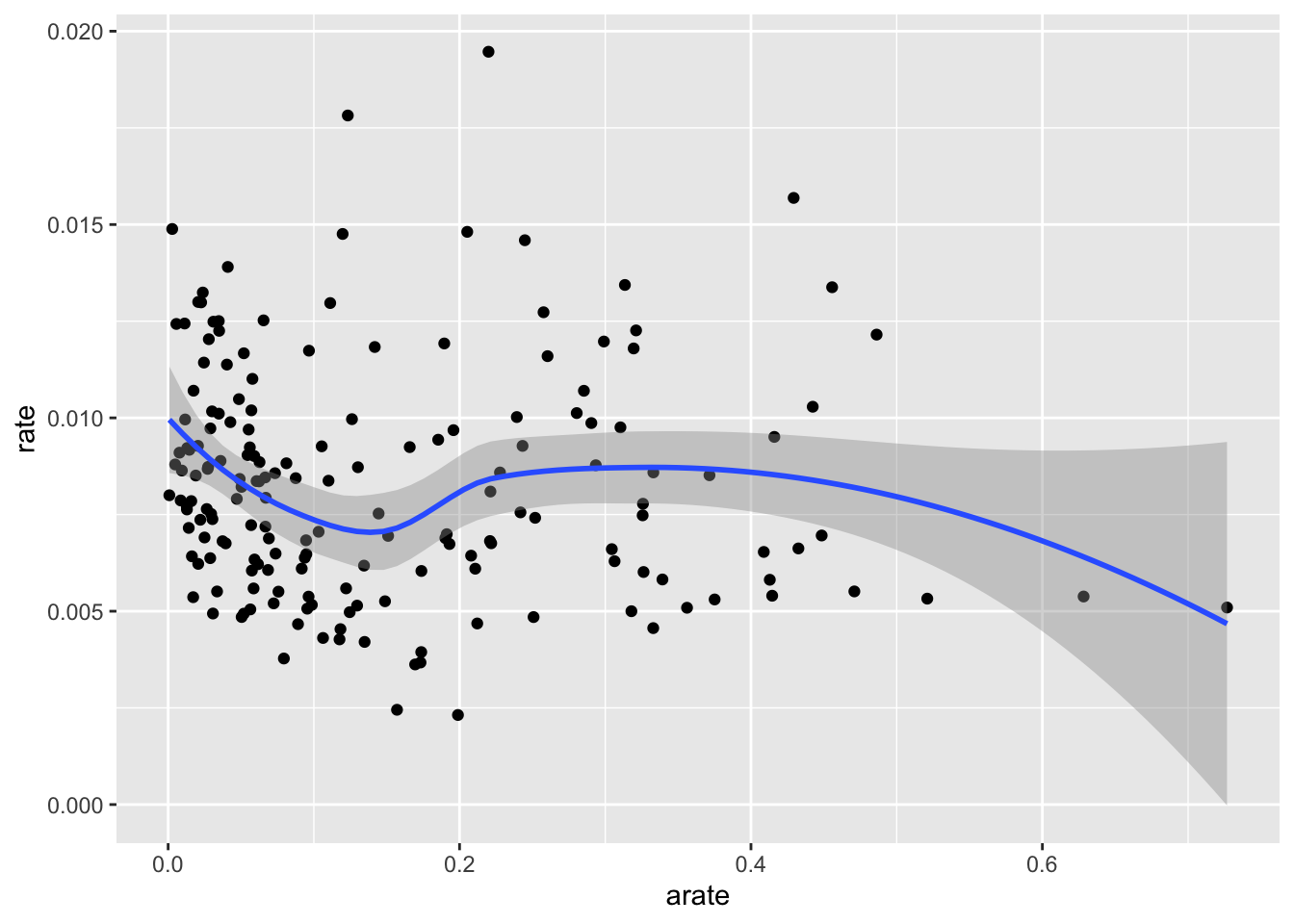
# 社区发病率与非裔比例
ggplot(zipnyc2,mapping = aes(brate,rate))+geom_point()+geom_smooth()## `geom_smooth()` using method = 'loess' and formula 'y ~ x'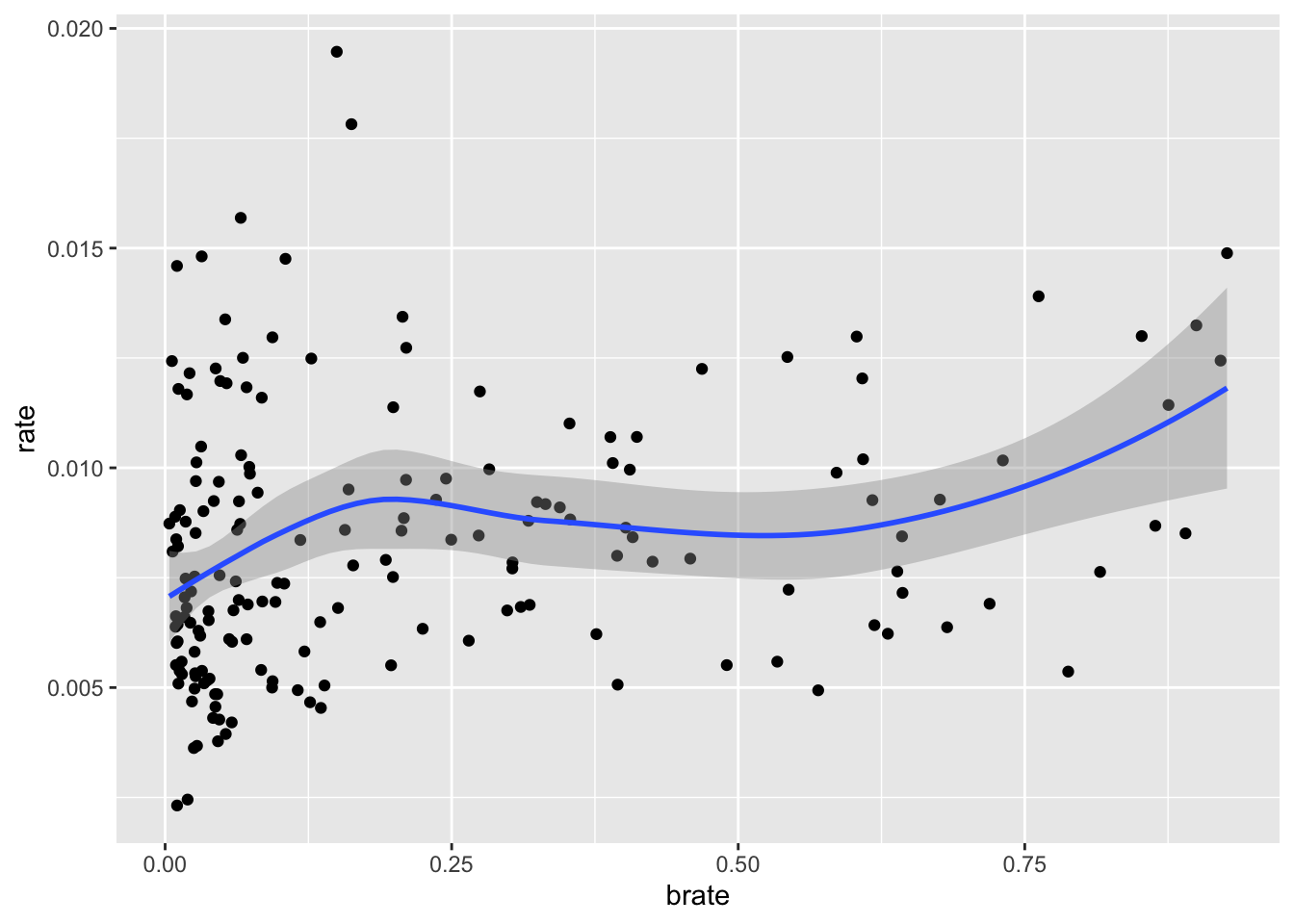
# 社区发病率与白人比例
ggplot(zipnyc2,mapping = aes(wrate,rate))+geom_point()+geom_smooth()## `geom_smooth()` using method = 'loess' and formula 'y ~ x'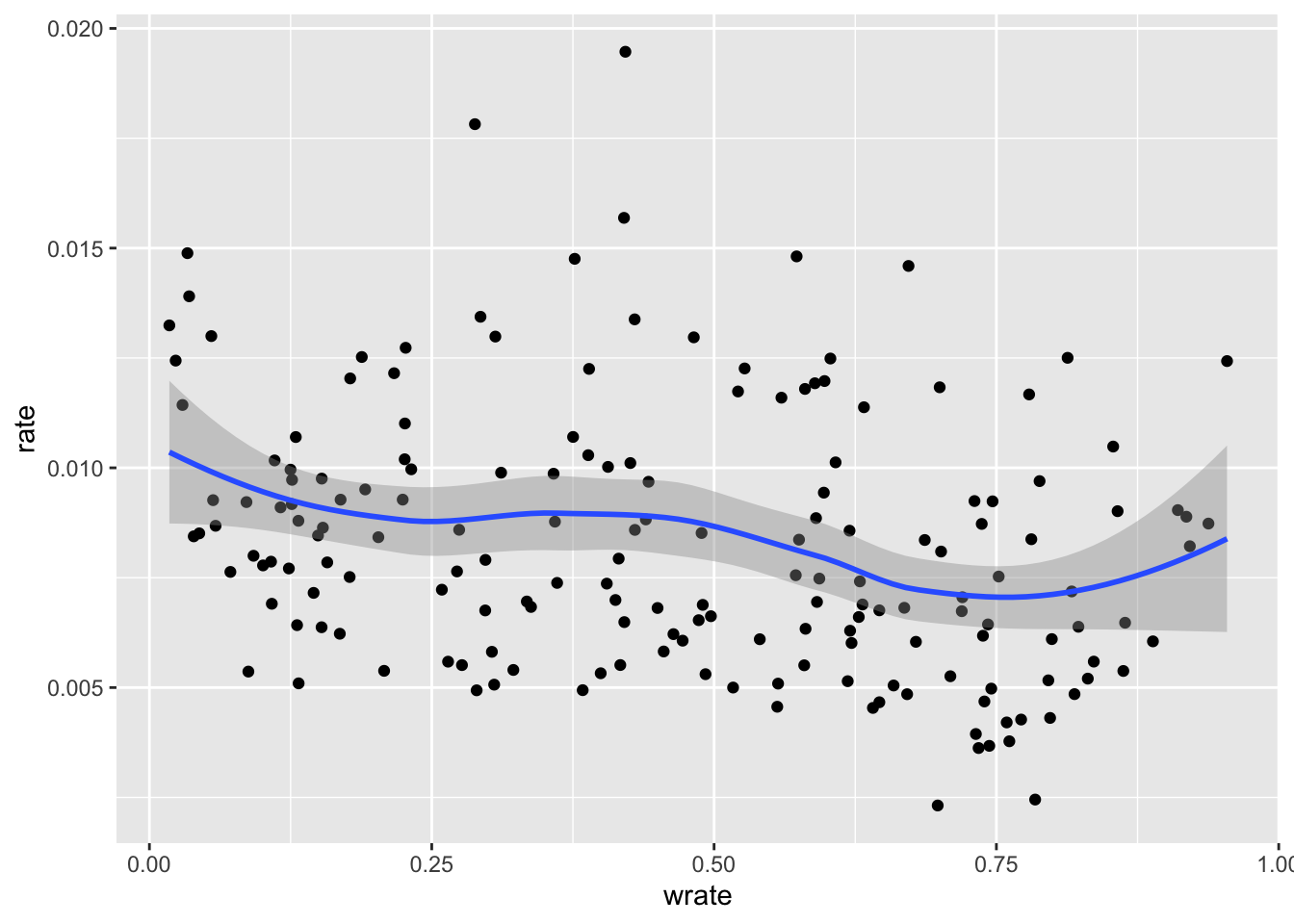
看起来收入超过9万美金,其社区发病率就会逐渐下降。非裔人口比例高,发病率会有所提高,白人则有个比例越高发病率越低的趋势。亚裔不明显,因为比例其实一直都不高。图上看你会感觉这个趋势很弱,但如果单纯线性回归其系数都是显著差异于0的,这里我就不去纠结p值的问题了。我们进一步看一下收入与族裔差异。
# 白人比例与收入
ggplot(zipnyc2,mapping = aes(medincome,wrate))+geom_point()+geom_smooth()## `geom_smooth()` using method = 'loess' and formula 'y ~ x'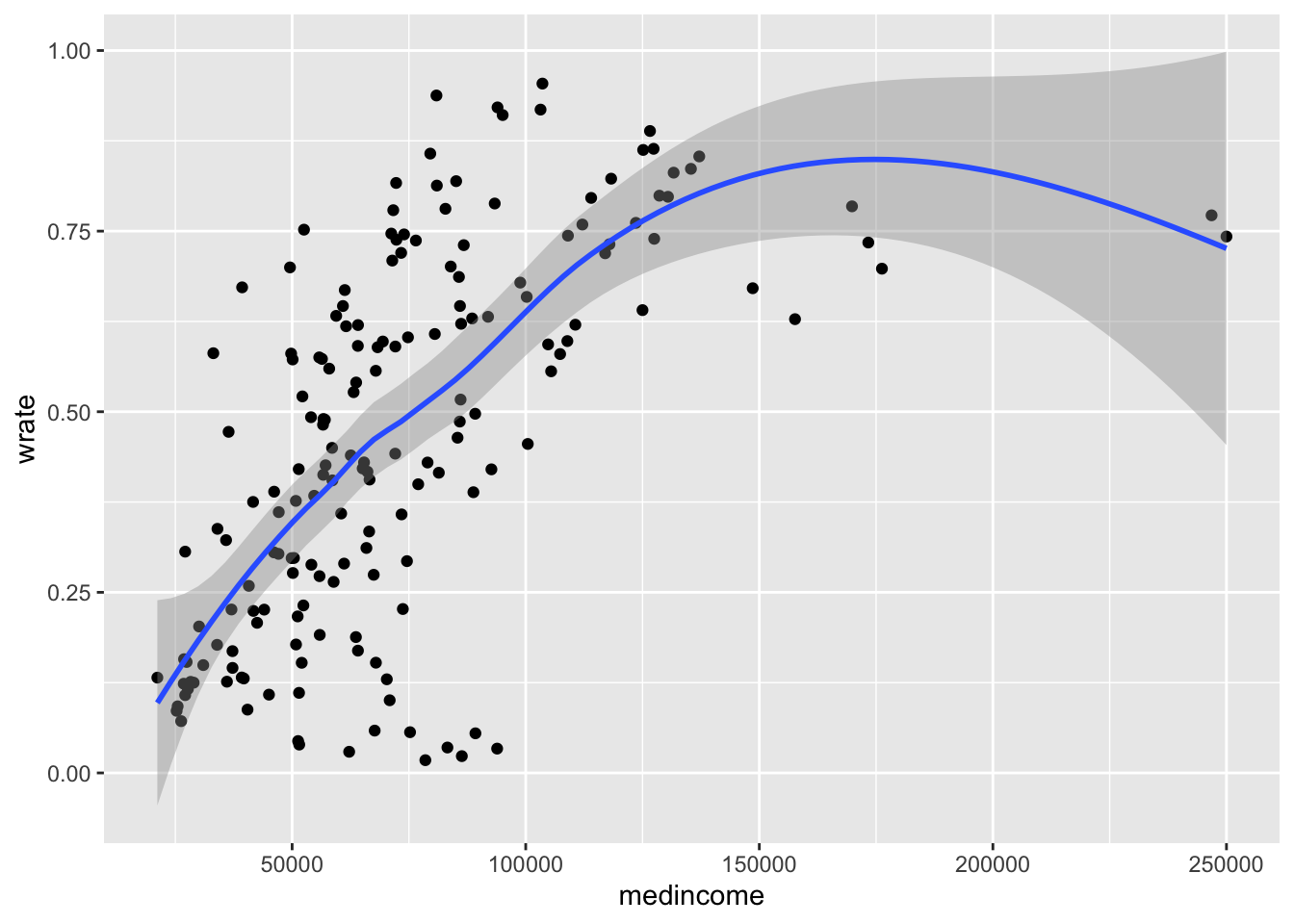
# 黑人比例与收入
ggplot(zipnyc2,mapping = aes(medincome,brate))+geom_point()+geom_smooth()## `geom_smooth()` using method = 'loess' and formula 'y ~ x'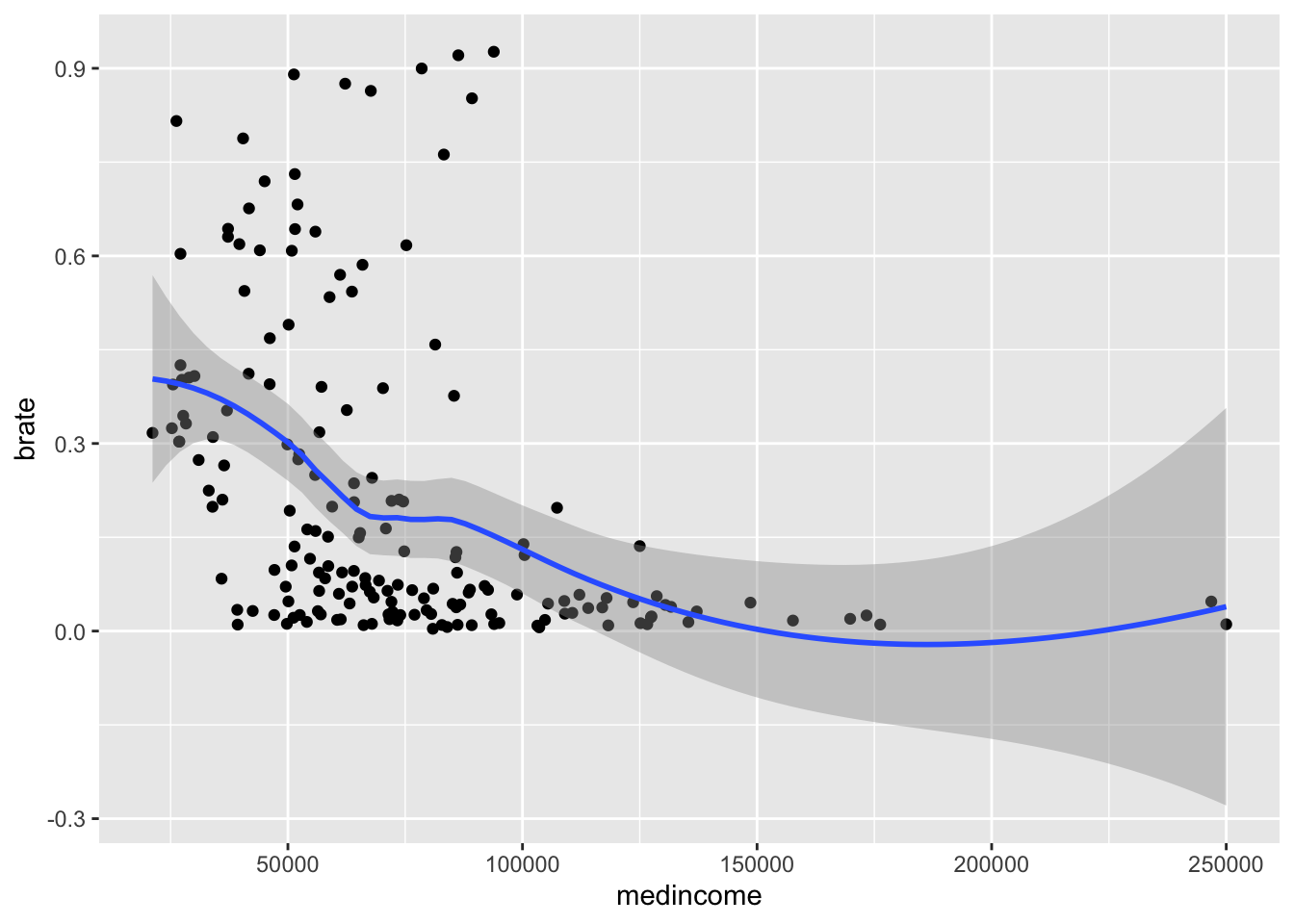
# 亚裔比例与收入
ggplot(zipnyc2,mapping = aes(medincome,arate))+geom_point()+geom_smooth()## `geom_smooth()` using method = 'loess' and formula 'y ~ x'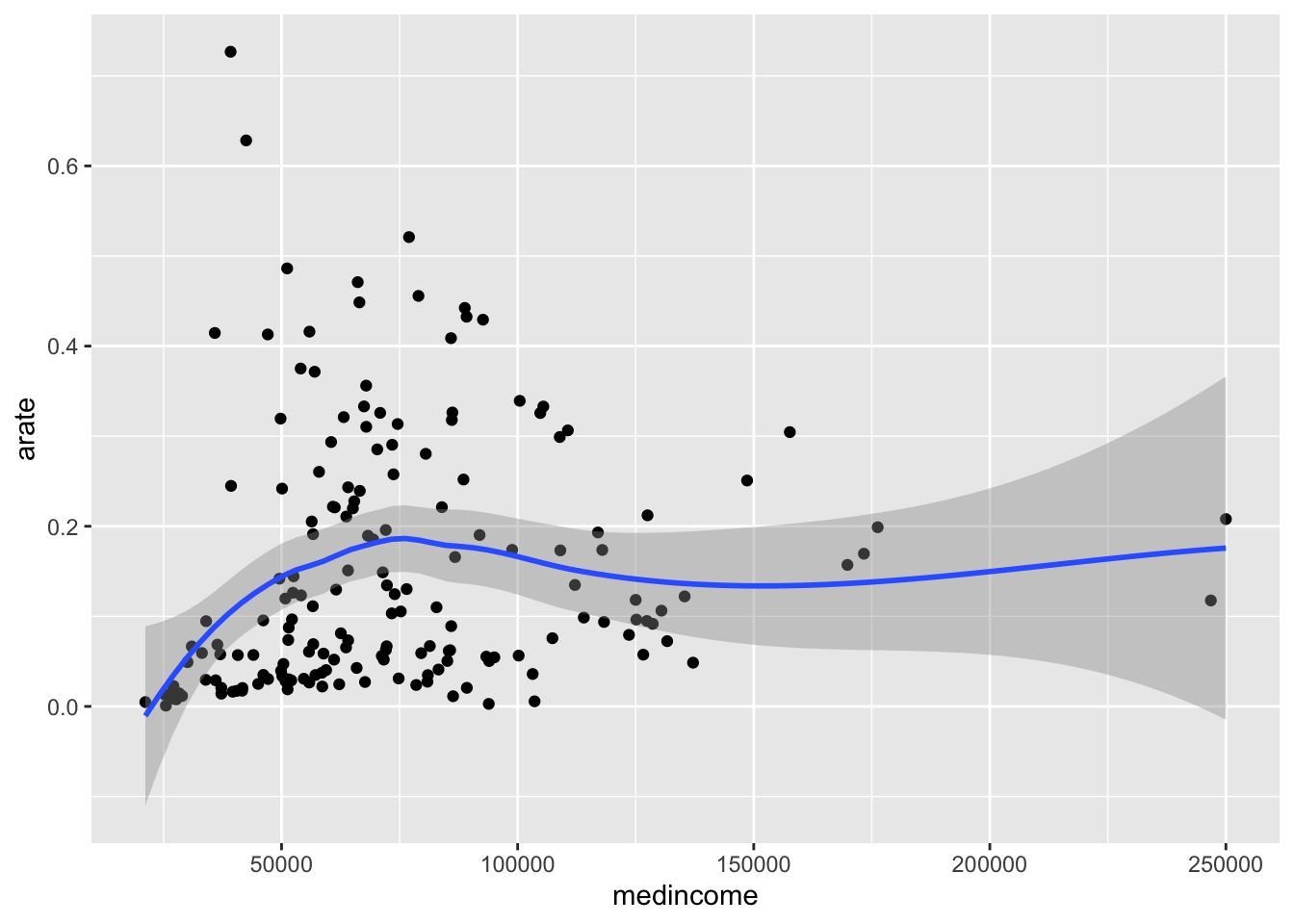
这里我们就有了个三角关系:族裔比例-收入-发病率。别的我就不说了,白人比例越高,收入越高,发病率越低。也就是说,虽然病毒传播是平等的,但经济收入差异会影响发病率,那么什么原因导致的呢?
个人防护用品其实全纽约都买不到,图上这个社区范围算不上能吃特供的人群,所以差异不应该在防护。非裔相比白人也许更喜欢互动,但保守的亚裔却没有出现白人那样的明显趋势。那么剩下的就是隔离了,也就是说,高收入的人隔离做得好。不对,应该这么说,高收入的人有条件隔离。要知道纽约的封城不是说完全封,而是非必要工种封,那么什么是必要工种?医护当然是,但更多的是那些 paycheck by paycheck 的工作,例如公交司机、环卫还有维修工等,这些人时薪很高但其实工时不长,结果就是他们的活动可能并未减少甚至更加繁忙,其得病风险也会比那些在家的人高。但这些人从来都没在媒体里出现过,你去采访个医生,他可以告诉你他们有多苦,你去采访个环卫工人,他们说话的逻辑都可能不是很通。媒体从来都只关心能发声的群体。他们从事最危险但必要的工作,而最后的赞誉与他们无关。这里有篇报道发现,中低收入者在居家令发出后其实并未减少活动,相比3%左右的病死率,吃不上饭风险可能更大。
当然,我不是说医护不该称赞,只是想说贫穷是更大的流行病,不解决贫穷,瘟疫就一直有藏身之处,他们不会出现在台面上的数据表里,但他们会存在。危险的工作总要有人做或被机器取代,但在那一天到来之前,不能忽视隔离背后的机会平等问题,在这个问题里我们可以看到族裔可能有机会不平等,收入也可能有机会不平等,甚至职业也会造成机会不平等。这里的平等是被传染的机会而不是其他,有人说病毒对所有人是公平的,其实真相可能更露骨与残酷。
我很清楚这里面有很多逻辑漏洞,数据支持也不完整,但至少这个基于网络开放数据的探索是可重复的。这个时代,虽然突发瘟疫的特效药可能短期不存在,但如果你有一个问题,就应该有开放数据可以正面或侧面回答,不要总是等答案。