最近参加了西奈山医学院举办的第二届暴露组学会议,其实我并没注册,只是实验室有位老师身体不适不想去了我去顶的包。暴露组学从名词提出了到现在大概10年有余,大约从去年开始进入高速发展阶段,判断标准就是论文数量,应该说今天的暴露组学大致处于20年前基因组学的发展阶段,方法还未成熟,标准尚未确定,不过都快成形了。
美国这边最早开始提暴露组的是NIH,加州伯克利、埃默里大学都是暴露组学起步比较早的地方,西奈山医学院 2017 年成立了美国第一家暴露组学研究所,借助美国医学院间的网络来推动暴露组学研究。从参会情况看也是很多其他高校附属医学院过来的同行,相信在接下来的10年研究经费与成果可能出现井喷,现在都是天使轮。
暴露组学研究什么呢?这里的基本问题跟基因组学差不多,是关于健康的。一个人健康与否基因组学认为更多依赖基因,而且伴随测序技术的进步,针对个人的测序已经是可负担的了。但暴露组学认为人的健康状态除了基因外还要考虑表观遗传、蛋白组、代谢组与日常暴露,甚至还要考虑诸如地理位置、社会经济地位、肠道微生物组等的作用。总体来看,健康是目标,预测变量却非常多,很明显不是一个单因素模型。
暴露组学属于面向问题的高度综合性学科,基础包括但不限于统计学、生命科学、数据科学、社会科学、环境科学、分析化学、毒理学、公共卫生、医学、遥感、传感、自动化、信息科学等诸多学科,我们目前并不知道哪个学科更重要,但很明显任何一个学科都可能成为回答终极问题的短板,而且就我个人观点而言,几乎每一个学科都有短板且学科间交流壁垒不是一般的高。
这里从环境分析化学与数据科学这两个学科来说下目前的问题。首先,当前如果要评价暴露水平,首先你得知道有什么,也就是目的性分析。但很遗憾,就暴露组学而言,我们并无法事先知道样品里有什么,所以更多研究是借鉴代谢组学的方法利用高分辨质谱来对未知物进行信息采集。信息采集的终点是色谱质谱峰,然而高分辨质谱全扫描的结果往往混杂大量源内反应形成的加合物、碎片或物质本身的同位素峰,这导致虽然我们可以同时收集上万峰,但形成这些峰的化合物可能只有峰数的十分之一且这些峰会共相关,如果你想讨论物质间的相关性而使用了峰数据,那么估计会有偏。同时,峰识别的算法也通常对全扫数据很不友好,你会看到大量不应该被当作峰的数据被选成了峰,积分效果也是一塌糊涂,这一点从分析化学角度是不可接受的。
另一个问题是对未知峰的标注,现在流行的方法是先跑全扫筛出差异峰,然后把那些峰去打二级质谱,有的则直接对差异峰去标注。这里我们暂时不讨论气相色谱质谱联用的数据,因为一般硬电离模式下碎片的特异性还算好,甚至可以用来定性。然而,就液相色谱而言,如果我们不考虑APPI这种非主流电离源,一般来说液谱往往使用ESI或APCI源,这两种都算软电离技术,一级质谱几乎看不到太多有价值的定性信息,此时使用一级质谱定性是风险很高的,下游的通路分析会因此不靠谱。而且就算找到一级质谱的匹配,你也无法确认是否是同分异构体,而同分异构体的生物活性千差万别,更不用说当前主流数据库各搞各的,覆盖范围有局限性,唯一的标注也并不意味定性。二级质谱定性当前有很多软件可以做,但基本都是欠拟合状态,训练用的数据基本依赖可获取标准或社区用户共享,想做未知物十分困难。
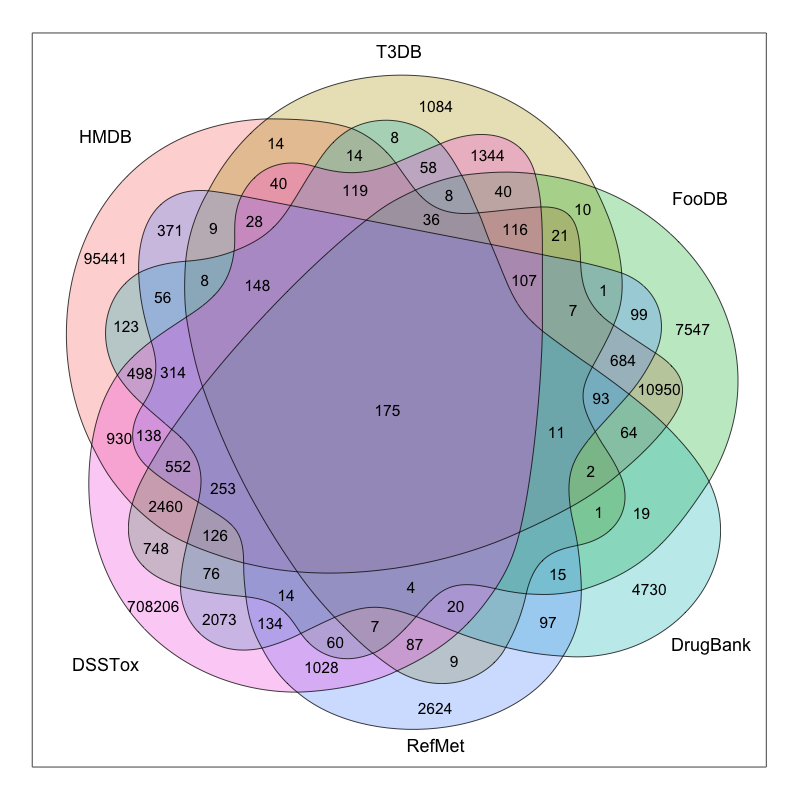
这是当前主流物质数据库的覆盖情况,其实最大的三个物质库(PubChem/Chemspider/CAS)我没列,因为数据搞不到或搞得到但处理起来太费劲,最大的应该是CAS,有1.4亿种物质,当然我们能接触到的应该只是其中很小一部分。代谢组学里用的最多的应该是 HMDB ,不过暴露组学看来这都属于生物内源物质,外源有生物活性物质也有诸如 DrugBank 或 ChEBI 或 T3DB 的库,工业品也有 HPV 库等等,但这些还算是有信息可查的,有些物质最多能生成个 InChIKey ,别的啥资料也没有。目前能汇总整理这些信息的地方并不多,而且我在处理有些库的数据时发现他们的数据整理问题很大,格式不标准,如果不是专业人士光是数据提取就得懵圈。
另外,分析通量也是一个容易被忽略的问题。假如你的样品有100个,每个样品30分钟,加上质控样品后一个序列大概能到150,这就是3-4天的连续分析,色谱柱会老化,甚至质量轴都会漂,当然你可以不断去校准。但最后的结果就是即便不是分批测样,同一批内部都会存在明显的批次效应。我常看到文章里说都控制好了,实际这个过程其实很难控制,随机化序列在一定程度上可以缓解但很难消除分析通量带来的定量不准。
即使分析上的问题都解决了,下面的问题就是统计分析了。用什么模型,为什么用这种模型眼下都没法检验,你也说不上哪个好哪个坏,其实都不怎么样。我看到过买几千个标来检验的,但问题是你设计非目的检测是想测未知的,也就是标根本可能覆盖不过来。而且统计模型的复杂性可高可低,一般说高了过拟合而低了欠拟合,不是说不能一次性尝试几百种统计模型或机器学习模型,关键如何解释?线性模型与层级模型是两种最有解释力的模型,但预测性能谁用谁知道,直接上神经网络不是不行,就是不好解释。精巧的统计模型面对错综复杂的数据,难怪临床上喜欢多元线性回归。
另一个相关问题是QSPR,代谢物或暴露物有差异一般都要反推回结构,通常临床研究是有明确终点的,但环境研究可能没有分组或者说分组后并无法进行效应预测。这个角度看是可以用效应诱导分析来做的,但效应终点还是相对固定。此时可以借助QSPR来同时预测多个毒性终点,不过如何把荷质比转成结构,前面说了,一团乱麻。其实多个毒性终点也意味着不同的健康模型,那么问题来了,有没有基于多个健康模型的宏模型呢?回答这个问题只能依赖合作研究了,单一领域其实都没搞特别清楚。
跟健康相关研究还有个问题就是无穷混杂因素,有的你知道例如年龄、性别、种族等,有的在建模时是忽略的,甚至根本意识不到可能是混杂因素。传统研究喜欢点对点做相关,组学研究是点对多做相关,健康研究的真相是多对多互相影响,控制实验当然是必要的,但如果数据是来自观测研究,那这问题就几乎无解,受研究共同体的视野限制。如果我们只关心那些强信号,可能忽略了那些弱信号,但这里的强弱是仪器决定的,不是生物学意义决定的。或许很多人的研究可以讲一个故事,但很难回答一个真实的问题。
前面说的问题只是现存问题的很小一部分,每一点的进展都可能对上下游研究产生颠覆式影响,对研究方法论的标准化、可重复化及与对基础研究进展的快速整合是必要的。或许十年后回看今天的暴露组学,很多人可能惊叹于为什么大量的资源被浪费在了毫无意义的研究上,不过这就是科研的现状,我们无法预知今天的愚蠢,但更重要的则是要意识到当前的问题。
处在新研究的黎明期即幸运也不幸,幸运的是大家起跑点都差不多,不幸的是只要你跑,摔跟头几乎是必然的。