前面说到在一个理想自发交易的稳态环境下,社会财富的分配会符合小球模型里的玻尔兹曼分布:
\[ f(E) = A e^{-E/E_c} \]
在这里,\(E_c\) 代表了温度,可以对应经济系统里总体财富的平均水平;\(E\) 代表了个人财富水平。这是个描述概率的指数函数,个人财富越多,越不可能出现。不过其实更多人熟悉的财富分配规律是二八法则,也就是帕累托-齐普夫定律,那么这个定律又是什么鬼?跟玻尔兹曼分布又有什么区别呢?
二八法则
二八法则属于观测定律,帕累托基于对人们收入的观察得出一个人收入高于\(x\)的概率为 \(Pr[X\geq x] = (m/x)^k, m>0, k>0,x\geq m\),\(m\)代表最低收入,也就是说,高收入的产生概率是指数的。齐普夫定律则描述的是语言学里的现象,认为第x个高频词的词频正比于其排序,例如一段文字里出现最多的词与第二多的词的词频大概是1:2.稍微推广一下就会发现这是个离散的指数或帕累托分布。
如果单独对齐普夫定律进行推广,那就到了曼德博(Mandelbrot)定律了,然后就成了调和数的一个特例。曼德博假设了一种字母语言来传递信息,并假设词的长度概率符合对数,也就是说越长的词虽然信息越多但增量越少,然后他计算了信息熵与平均词长,发现熵低的时候就会出现齐普夫定律。之后米勒(Miller)设计了猴子打字机,把随机空格当成词的间隔,结果发现这样生成的词也符合齐普夫定律,这样就说明齐普夫定律实际上不依赖指数分布就能生成。
这里我们就直接来仿真下看看,这里我们设计一种只有十个字母的语言:
string <- sample(c(LETTERS[1:10]," "),size = 100000,prob = c(rep(1/12,10),1/6),replace = T)
stringl <- paste(string, sep="", collapse="")
strings <- strsplit(stringl, " +")
t <- as.numeric(table(strings)[order(table(strings),decreasing = T)])
plot(log(t/sum(t))~log(c(1:length(t))),pch=19)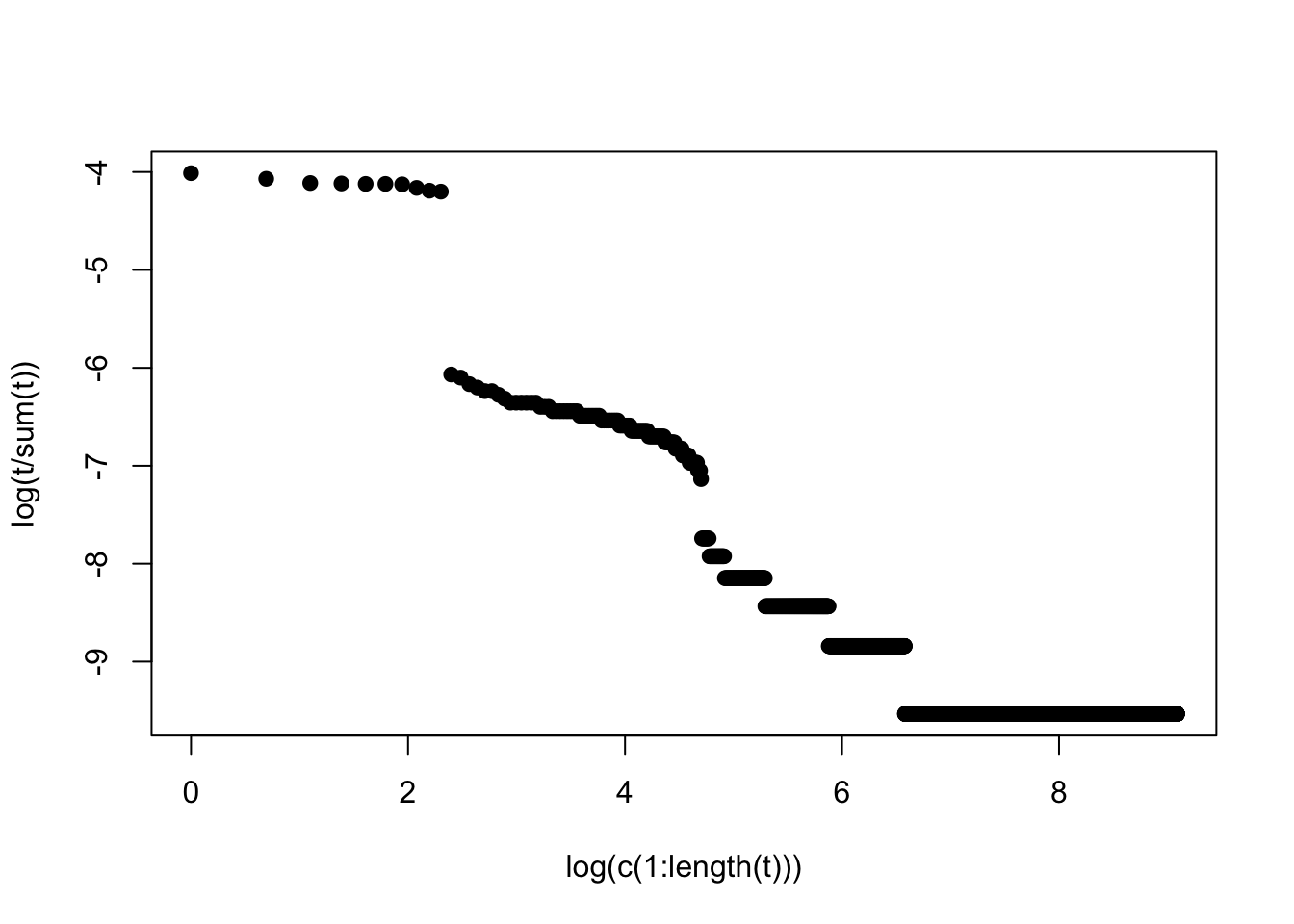
怎么说呢,要是不考虑前十个全是单一字母,整体看随机过程就会产生齐普夫定律描述的现象。这就不同于能量交换问题了,当然如果你把字符长短的信息量考虑成能量,那么本质上这个随机过程跟我们之前说的玻尔兹曼分布存在一定的对应可能。
另一种对其生成原理的解释来源于网络的生成过程。考虑多个点,其连接过程中如果被连接的点连接得到新连接概率正比于其已经获得的连接数,那么最后生成的网络就是一个度符合指数分布的状态。从语言学角度看就是一个开始随机选择的常用词会因其使用频率高而更容易获得新词的连用。齐普夫自己则提出了一个基于最小努力原则的解释,看起来跟这个网络生成过程有类似的地方。
从这里我们可以看出,不论那种生成过程,似乎都是起源于一个概率空间大于资源空间的状态。对应到财富问题就是总财富有限,对应到语言问题就是词的排列组合空间大于现实描述空间,对应到网络就是连接数少于节点数。在这个情况下,分配会自发走到少数人掌握更多资源的状态。
本福德法则
既然提到了齐普夫,就可以顺道说下本福德法则。本福德法则认为数字中第一位数字里1出现的概率高于2,2高于3,以此类推。直觉会认为数字中出现概率是相等的,但真实数字都是自然生成的,要想得到3,必然要经过2,更必然经过1。因此考虑这个生成过程的话1出现在第一位的概率自然要很高,特别是数据跨越多个数量级的时候。这个法则经常用在虚假数据检测上,不过也不是说不能跳过去:
t <- round(runif(10000,1,100000))
x <- c()
for(i in 1:10000){
x[i] <- as.numeric(head(strsplit(as.character(t[i]),'')[[1]],n=1))
}
t <- as.numeric(table(x)[order(table(x),decreasing = T)])
plot(t/sum(t)~as.numeric(names(table(x)[order(table(x),decreasing = T)])),pch=19)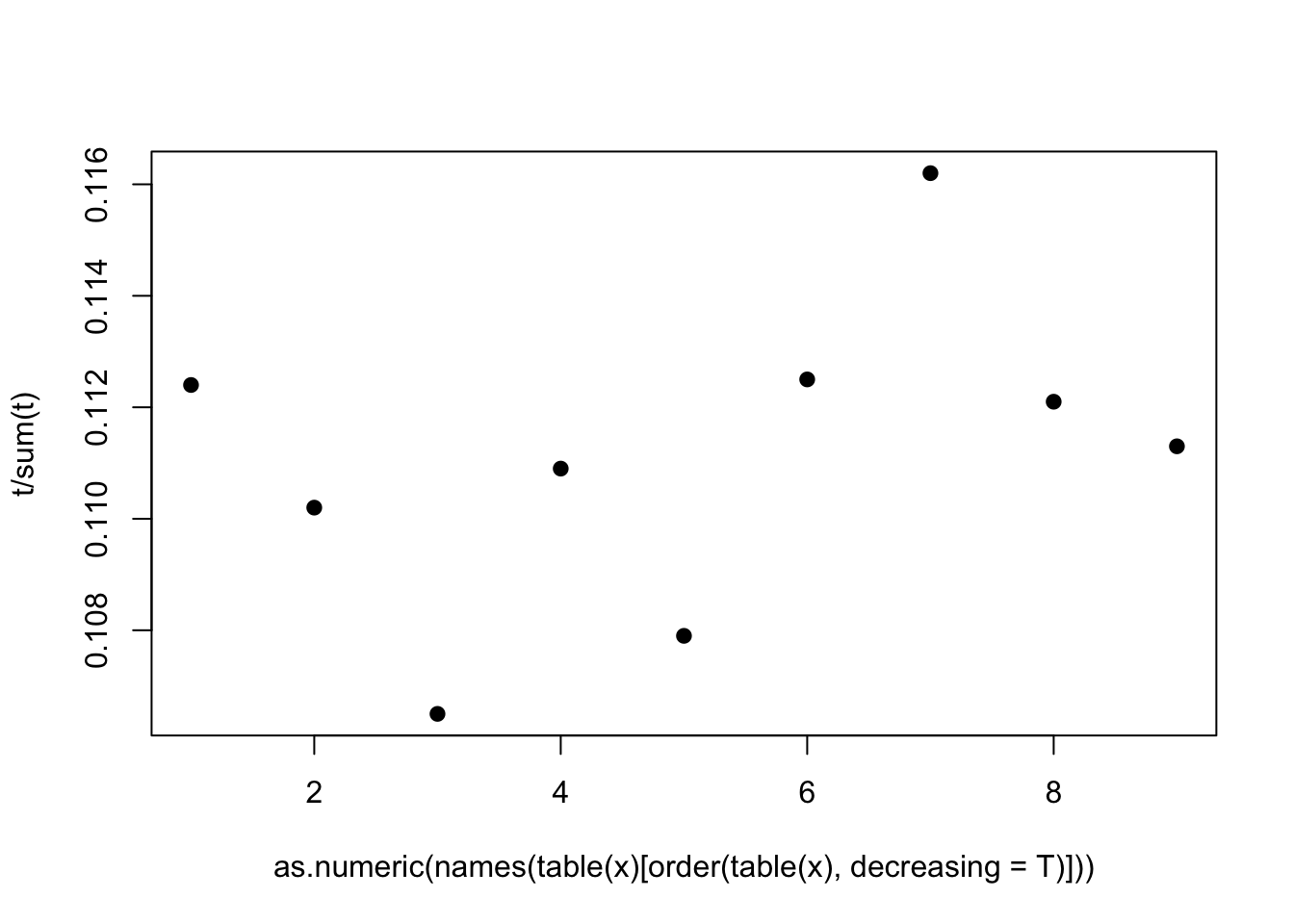
这里我们看到本福德定律没有出现,各数字概率几乎相同。
t <- round(runif(10000,1,100000)) + (1:9)^(round(runif(10000,1,9)))## Warning in (1:9)^(round(runif(10000, 1, 9))): longer object length is not a
## multiple of shorter object lengthx <- c()
for(i in 1:10000){
x[i] <- as.numeric(head(strsplit(as.character(t[i]),'')[[1]],n=1))
}
t <- as.numeric(table(x)[order(table(x),decreasing = T)])
plot(t/sum(t)~as.numeric(names(table(x)[order(table(x),decreasing = T)])),pch=19)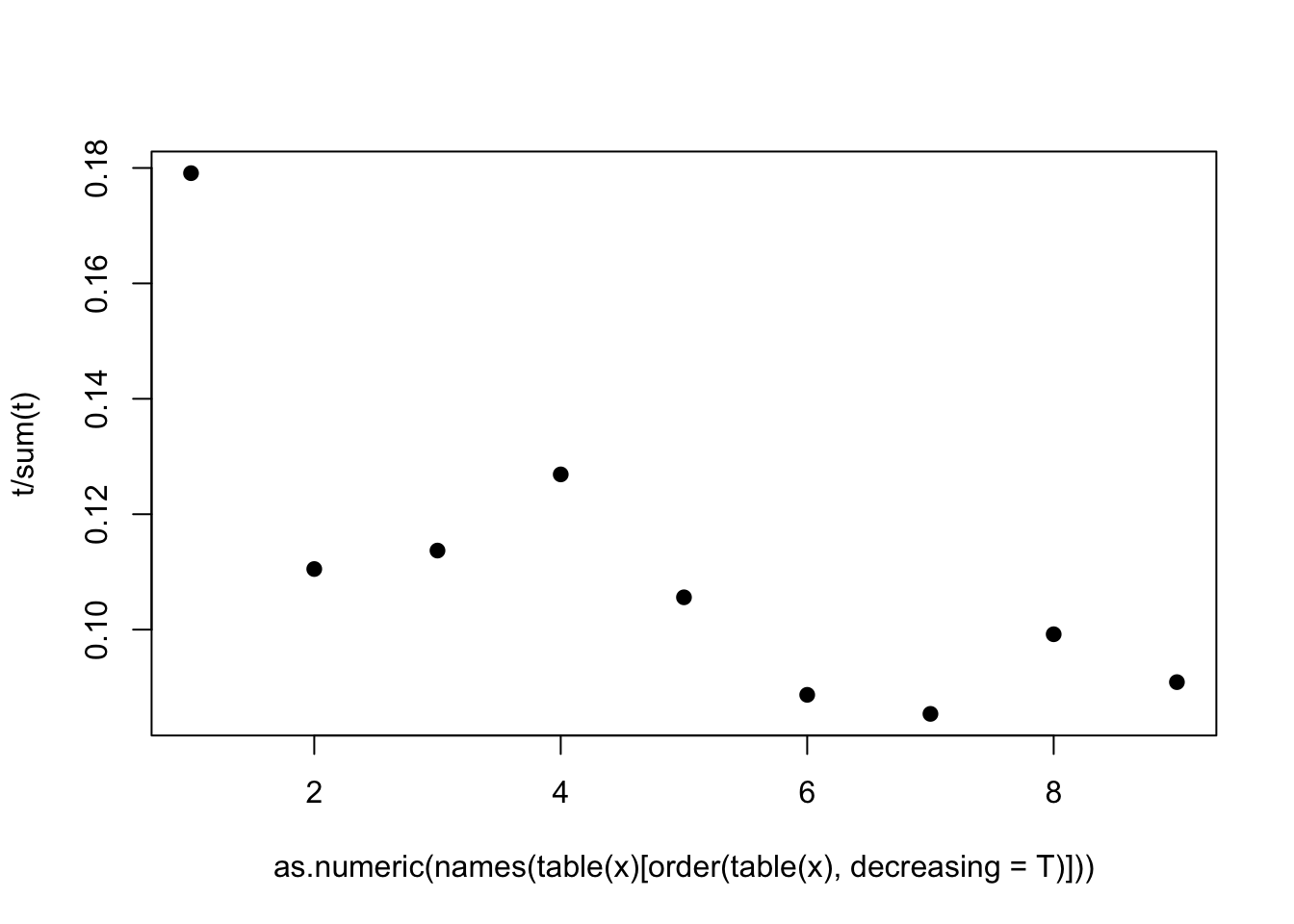
这里,通过加入不同尺度的随机数,我们虽然不能完全模拟本福德定律,但至少可以在一定程度上重现本福德定律出现的条件与结果。陶哲轩的博客上有一篇专门讨论本福德定律与二八法则的文章,因为比(du)较(bu)长(dong),我在这也就不解释了,还是回到财富分配问题上。
热机模型
在进一步讨论前,我们需要界定一个问题:玻尔兹曼分布只考虑了分配而没考虑创造,也就是能量输入,现实世界中是存在新财富创造的动力学过程的,如果这个过程稳定我们也可以进行定量考察。假定我们有一个工厂,这个工厂的产品属于精准定位产品,只有部分人达到某种财富时会购买。那么在怎样的比例下会最大化厂家的收益?如果财富分配总体是指数的,那么价格\(p\)以及财富分配\(f(p)\)的乘积就决定了收益。这里\(f(p)\)是个指数函数\(e^{-p/p_{a}}\),然后我们就求导数吧,结果就是价格要等于社会平均财富\(p_{a}\)。此时财富分配概率会给出\(1/e\),也就是大概0.37的比例。换句话说,定价要定到大概不到四成的人买得起时厂家收益最大。
不过如果社会在发展,一部分厂家财富远高于另一部分,例如发达国家与发展中国家,那么此时我们就得考虑两个热机。跨国公司为了卖出产品要引导发展中国家人民的消费需求,也就是先投资让发展中国家富起来然后定价去获取0.37比例的富人。长期看对公司实体而言是赚的,但两个热机开启能量交换还是会导致新的指数分布或者说最终的热寂,后果就是两国富人会有类似的收入而老百姓仅仅就是维持生存。由于先发优势,发达国家里的非富人会逐渐体会到系统性收入停滞,发展中国家的非富人则通常会陷入中等收入陷阱。自发性财富分配不均政府很难插手,因此社会福利等机构会最终称为政府的首要支出,否则会出现经常性暴动、民粹主义及宗教冲突。
债务模型
现实世界的残酷在于依赖价格歧视构建的商业体系甚至不需要四成人,而仅仅采用一些游戏规则的引导方式就可以获取更多人的利润,最简单的方式就是提供借贷服务。借贷根源上看就是透支未来的收入参与今天的经济行为,这使得很多事变成可能,但也预支了繁荣。这里我不想评价优劣因为很多事实给出的答案是完全相反的,不过我们可以继续讨论财富的分配。
如果允许借贷,那么系统内凭空就会多出很多能量,也会出现更多的稀有级别超级富豪。同时,很多人就会出现负能量,这情况对应现实就相当于个体破产了,如果借贷相当,那么此时财富分配就会是一条跨越0点的更平缓而长尾的分布。翻译成人话就是这样的封闭经济系统长期运行会逐渐把大多数人推到负资产区。这里需要清楚的是此时分布已经不能用没有负值的玻尔兹曼分布来描述了,虽然形状可能差不多。
真实社会
真实社会财富分配是什么样的我们是可以从统计数据里得到部分答案的,之所以是部分是因为很多财富持有者避免暴露自己来避税或避世。在《平均的终结》这本书里,作者指出工业标准化实际是在给大多数人做平均,平均后的社会井井有条符合标准。然而,这种标准化却会是反人性的。更重要的是,财富会自发形成指数分布,而且除了自发还有自私,现在二八法则已经被互联网更新为九十九一的法则了,只有极少人会被长期关注。即便是号称撬动世界发展的区块链也如此,有人分析了比特币上的交易,结果发现初期不流行时交易网络非常混乱无序,但在经历了大涨后也出现了依附偏好的网络构建特征,最后也形成了指数度分布,然后后期的交易也符合了财富的指数分布。虽然比特币是去中心的,但不平等的财富分布却一点也没变,当我们以为创造历史的时候,我们其实只是重写了人性的过往。
为了延续已经存在的优势,已经富裕的个体与国家都会去投资科技与教育来开源,因为截流相当于对民众的道德绑架。在《我们的孩子》这本书里,作者认为收入不平等直接造成了教育的机会不平等。所谓机会不平等很大一部分在于试错风险,高收入家庭的孩子可以尝试高风险高收益,失败可以重来,低收入家庭的孩子则自发拒绝试错,因为错一次就意味着之前努力全部白费。然而,这种微小的选择差异会造成后期发展的巨大区别。有人说穷人可以光脚不怕穿鞋,那是体力劳动,现代社会知识鸿沟基本就是收入鸿沟,你就算甩开了膀子也不能让你操作高精尖仪器。你会看到富人孩子们不分国籍、种族、宗教信仰而得体大方地跟彼此交流,而穷人则纠结于国籍、种族、宗教信仰等标签为生存战战兢兢。这一切似乎都在小球的碰撞里注定而人的自由选择权似乎越来越小。
美国1980-2014年,收入前十万分之一的人财富增长616%,1%的人增长194%,底层20%的人只增长了4%,收入的幂律分布可能对新技术的高投入研发与提高市场活力有益,只是受益人可能也只是那前1%,民众通过票权重新洗牌的风险越来越高,然后我们就看到川建国。保罗·福赛尔为美国社会划分了九个阶层,那本《格调》放在今天看都描述精准,讽刺的是很多国内新贵买来当成了指南。其实,最近几年讨论的全球尺度财富分配不均扩大化并不限于现代社会,考古学家计算了幼发拉底河流域文明到庞贝古城的基尼系数,发现这1000年来财富不平等是不断加剧的,农业文明的出现可能是背后推手,因为财富的积累在农业社会比游牧采集社会更容易发生。很多跨国公司想在印度重现中国的中产爆发潮,结果惨淡,财富在全球尺度内都在向精英超量累计,这个时代(也就起始于近两年)已经不容易造就中产了,大众购买力上不去很难谈发展。说白了原来以国家为单位的热机被全球化整合成了一个,如果你没赶上窗口期,后面就是长期停滞。
启示
了解现状不是为了向其妥协,而是更好引导解决其中的问题。物理上也好数学上也罢,我们的确会看到财富会自发形成符合指数分布的分配模式。然而,物理也好数学也罢,规则是无法改变的而社会财富的规则是可以改变的。我们有税收有社会福利也有个体间的互助合作,二次分配这类规则可以在共同认同基础上让所有人都生活更满意,这需要智慧而不是啥都不做听天由命。即使从模型来看,只要我们突破假设,规律也就不会成立,例如普惠技术的跨越式发展及可持续商业模型的广泛应用。财富分配不均也许算不上问题只是个现象,每个人的幸福可能才是更终极的追求,对此我们需要更灵活的游戏规则。