背景
Kaggle是一个线上数据科学竞赛类网站。简单说,上面会提供数据与需求,目的是构建一个\(f(x) = y\)的模型。参赛者会得到一个有\(x\)与\(y\)的训练集与只有\(x\)的测试集,你需要在训练集上构建模型,输入测试集的\(x\)得到你预测的\(y\)。之后你需要提交你的\(y\)到Kaggle,它会计算一个正确率作为竞赛的评判标准,分数高的会有奖金或仅仅是个荣誉。对于入门者,Kaggle提供了一个泰坦尼克号幸存者项目作为入手项目,项目提供的数据就是泰坦尼克号上乘客的信息与其幸存状况数据,以上为背景。
数据准备
名为train.csv的训练集数据与test.csv的测试集数据可从网站上下载,请将其移动到工作目录并读取。
# 读取数据
train <- read.csv('train.csv')
test <- read.csv('test.csv')
# 观察数据结构
str(train)## 'data.frame': 891 obs. of 12 variables:
## $ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
## $ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
## $ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
## $ Name : Factor w/ 891 levels "Abbing, Mr. Anthony",..: 109 191 358 277 16 559 520 629 417 581 ...
## $ Sex : Factor w/ 2 levels "female","male": 2 1 1 1 2 2 2 2 1 1 ...
## $ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
## $ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
## $ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
## $ Ticket : Factor w/ 681 levels "110152","110413",..: 524 597 670 50 473 276 86 396 345 133 ...
## $ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
## $ Cabin : Factor w/ 148 levels "","A10","A14",..: 1 83 1 57 1 1 131 1 1 1 ...
## $ Embarked : Factor w/ 4 levels "","C","Q","S": 4 2 4 4 4 3 4 4 4 2 ...str(test)## 'data.frame': 418 obs. of 11 variables:
## $ PassengerId: int 892 893 894 895 896 897 898 899 900 901 ...
## $ Pclass : int 3 3 2 3 3 3 3 2 3 3 ...
## $ Name : Factor w/ 418 levels "Abbott, Master. Eugene Joseph",..: 210 409 273 414 182 370 85 58 5 104 ...
## $ Sex : Factor w/ 2 levels "female","male": 2 1 2 2 1 2 1 2 1 2 ...
## $ Age : num 34.5 47 62 27 22 14 30 26 18 21 ...
## $ SibSp : int 0 1 0 0 1 0 0 1 0 2 ...
## $ Parch : int 0 0 0 0 1 0 0 1 0 0 ...
## $ Ticket : Factor w/ 363 levels "110469","110489",..: 153 222 74 148 139 262 159 85 101 270 ...
## $ Fare : num 7.83 7 9.69 8.66 12.29 ...
## $ Cabin : Factor w/ 77 levels "","A11","A18",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ Embarked : Factor w/ 3 levels "C","Q","S": 2 3 2 3 3 3 2 3 1 3 ...# 观察输出
table(train$Survived)##
## 0 1
## 549 342根据输出的预测
初步探索可知,我们的自变量有11个,因变量为二元输出。因为活下来的要多过幸存的,我们最保守的模型是基于输出的,也就是预测测试集上的乘客都没幸存。提交,正确率63%,目前估计要排到2000+。
test$Survived <- rep(0, 418)
# 按照Kaggle要求构建数据框
submit <- data.frame(PassengerId = test$PassengerId, Survived = test$Survived)
# 写为csv文件
write.csv(submit, file = "alldie.csv", row.names = F)考虑单一分类变量
OK,现在我们开始考虑使用自变量来进行预测,先考虑分类变量性别。
# 构建分类列连表
prop.table(table(train$Sex, train$Survived))##
## 0 1
## female 0.09090909 0.26150393
## male 0.52525253 0.12233446第一个模型预测了全部死亡,现在我们看到如果性别为女性,幸存概率要高很多,那么考虑这个变量后我们就在第一个模型基础上预测如果性别为女就能活下来。
# 第一个模型
test$Survived <- 0
# 考虑性别变量
test$Survived[test$Sex == 'female'] <- 1
# 按照Kaggle要求构建数据框
submit <- data.frame(PassengerId = test$PassengerId, Survived = test$Survived)
# 写为csv文件
write.csv(submit, file = "alldiebutfemale.csv", row.names = F)OK,目前正确率77%,大概排1800+。
考虑连续变量
我们现在考虑下连续变量年龄,看看分布。
# 绘制直方图
hist(train$Age)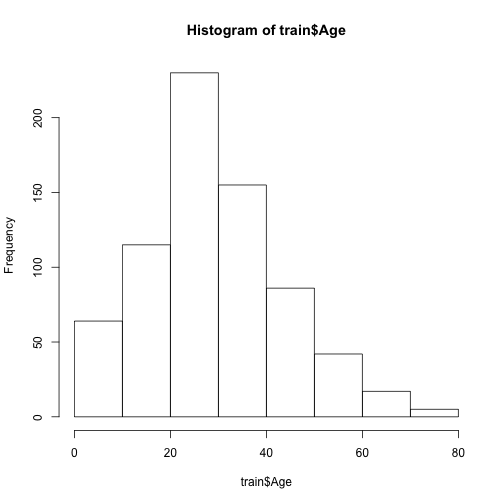
plot
按照当年看过的电影,妇女,老人,小孩应该是优先上救生船的,因此我们认为小于20岁跟大于60岁的乘客更容易幸存,探索下。
train$oldchild <- 0
# 提取老弱
train$oldchild[train$Age < 20 | train$Age > 60] <- 1
# 看看女性部分
aggregate(Survived ~ oldchild + Sex, data=train, FUN=sum)## oldchild Sex Survived
## 1 0 female 177
## 2 1 female 56
## 3 0 male 81
## 4 1 male 28额,似乎不太对,好像老幼女性死的更多,看来电影与事实有出入,那么我们反着预测试试。
# 第一个模型
test$Survived <- 0
# 考虑性别变量
test$Survived[test$Sex == 'female'] <- 1
# 老弱可能要挂
test$Survived[test$Sex == 'female' & (test$Age < 20 | test$Age > 60)] <- 0
# 按照Kaggle要求构建数据框
submit <- data.frame(PassengerId = test$PassengerId, Survived = test$Survived)
# 写为csv文件
write.csv(submit, file = "alldiebutfemalemiddleage.csv", row.names = F)额,正确率73%,比刚才低了。回想一下,我刚才做的不过就是不断的分组,甚至是连续变量分组,这样到一定程度就会数据稀疏到欠拟合。同时因为分组中另一组简单认为幸存或不幸存也造成了较大偏差,所以整个模型都不好了。如果我们深入回想,现在需要的是一点过拟合,通过不断分类来确定最终分类其实就是种了一颗决策树,那么我们应该试试决策树。
决策树
决策树的原理很简单,就是不断寻找能将数据分成区别最大的两块的阈值,然后再到下一层去迭代寻找,直到你的子分类中全是一样的输出。具体到这个例子,我们需要考虑用那些变量:PassengerId没啥意义;Name也看不出跟输出有什么显性联系;Ticket上的编码长得像密码,不要;Cabin数据残缺严重,不要;Embarked是上船位置,似乎跟沉船也没啥关系,不要。上面是一个主观变量的筛选,其实如果依赖专业知识会更快,当然也有基于统计学的变量筛选,暂时不提。决策树你就看作\(f\)就可以了,算法别人都写好了。
# rpart包里的函数要比tree好些
library(rpart)
fit <- rpart(Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare, data=train, method="class")
plot(fit)
text(fit)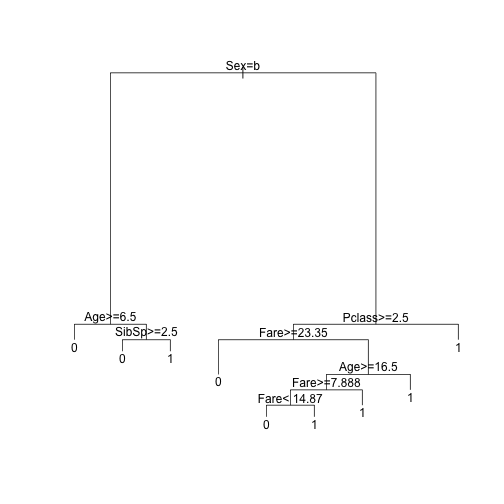
plot
从结果上看,第一变量是性别:对男性而言,年龄是第二分割点;对女性而言,仓位则成了第二分割点,所以决策树的分割相对还是比较精细的。我们用预测函数得到结果看看:
Prediction <- predict(fit, test, type = "class")
submit <- data.frame(PassengerId = test$PassengerId, Survived = Prediction)
write.csv(submit, file = "tree.csv", row.names = FALSE)这次正确率达到了79%,光荣挺进前1000。
交叉检验
前面我已经隐约提到了过拟合与欠拟合的问题,当你模型过分依赖训练集数据时,数据会过拟合;反之模型太不依赖训练集,例如最初我们用输出变量预测的状况,数据就会欠拟合。过拟合会导致模型捕捉了原始数据中的细节噪声,模型整体变异度也就是方差大,输出不稳;欠拟合则会导致模型没有识别到数据中的结构,不管你怎么变换自变量输出都不变,也就是偏差大。说到这里你也就清楚了,这不就是bias-variance tradeoff吗!这样说来,我们就可以使用一些统计学习的方法来构建更稳健的模型,例如交叉检验。你可以将交叉检验理解为降低过拟合风险的方法,实际上有些机器学习算法例如人工神经网络几乎可以完全拟合训练集,这时我们需要加点正则项或者叫惩罚函数来模拟过拟合的状态,进而生成预测性能良好的模型或者就直接用交叉检验。
交叉检验一般把训练集分个5到10份,每次训练留一份作为检测集,根据检测集结果调整模型参数,迭代直到参数不变化。这样我们模型虽然没有惩罚函数,但不断的调试可以保证参数不会过拟合到一类数据上。不过也不用演示了,在rpart包里默认就有交叉检验了,刚才你用默认的算法去做就已经包含交叉检验了。
其他算法
基于决策树的算法中有种叫做随机森林的算法效能不错,其逻辑在于随机抓一把变量来生成决策树,重复多次,然后对结果取均值或投票。这样就相当于加了一个惩罚函数,要知道决策树是没有惩罚而只能通过交叉检验来提高效能。这里面age的缺失比较重,为了去除缺失值,我们可以考虑用其他变量建个决策树补一下空白。
# tree 补下age的缺失值
Agefit <- rpart(Age ~ Pclass + Sex + SibSp + Parch + Fare,
data=train[!is.na(train$Age),], method="anova")
train$Age[is.na(train$Age)] <- predict(Agefit, train[is.na(train$Age),])
library(randomForest)
fit <- randomForest(as.factor(Survived) ~ Pclass + Age + Sex + SibSp + Parch + Fare, data=train, ntree = 2000)
Prediction <- as.numeric(predict(fit, test))-1
submit0 <- data.frame(PassengerId = test$PassengerId, Survived = Prediction)
# 预测出的缺失值用决策树结果充数 这可看作模型嵌套
submit0[is.na(submit0$Survived),2] <- submit[is.na(submit0$Survived),2]
write.csv(submit, file = "randomforest.csv", row.names = FALSE)结果跟决策树差不多,不过这种01输出的数据结构其实也可以用广义线性模型中的logistic回归来做。或者你也可以尝试人工神经网络,支持向量机,岭回归,lasso什么的,等你都尝试一遍后基本该遇到的情况就都遇到了,那个时候就该尝试进军其他挑战了。