科学研究的一个基本要求就是可重复(Replication),但很现实的一个问题就是不是每个实验都可以被重复。有很多研究是一锤子买卖的,例如测试某种污染物毒性的动物暴露实验,一个实验周期3到6个月,独立研究人员重复三次加上写文章发表的过程要2年,这时候如果另外有独立课题组也想重复这个实验,时间成本与资源成本是很不合算的,而且重复别人工作的项目你很难拿到基金去支持,后续发表也可能因新意不足被拒稿。实际点说,脑子不进水的研究组是不会轻易去重复一个理论上可重复,耗用时间人力经济成本高而实际意义又不那么明朗的实验的。很多大项目或者研究人员想知道的问题很有可能全世界独一份,例如探月,探火星,当前技术条件下除了研究人员自己的重复也很难找到另一份可参考的报告来评价这个工作,这就是可复算性研究(reproducible research)出现的第一个背景。
第二个背景就是当今实验数据处理本身已经也存在重复性问题,例如原来搞测序跑胶,几个月才能搞明白一个蛋白序列,现在有组学技术,你搞个二代测序,分分钟(夸张,实际也得几天)搞定单体基因组。但与几十年前不同的是,原来你是带着问题找答案去设计实验,现在技术进步了,一下出来一堆数据,而这一堆数据里面你的问题可能解答了,但也可以去解答另一些问题,甚至面对同一批数据,不同研究组可能得到不同的结论。这个问题的核心就是数据处理步骤也需要可重复性。杜克大学有过一个很有名的案例,一个进入到临床阶段的抗癌药物被发现在离体实验阶段被标错了号,也就是后面三年的工作都是无用功,这个损失是很大的,而且问题并非出现在实验阶段,而是数据处理过程的失误。据此,约翰霍普金斯大学的Roger D. Peng副教授就在science上撰文提出,不妨假定实验操作是正确的,让研究人员提供公开的原始数据,这样一方面我们可以对数据处理过程进行验证,另一方面也说不准能从原始数据中发现新的问题或现象。这样当论文作者提供了原始数据与处理代码后,其他独立研究人员可以直接去评价代码质量。在实验流程越来越标准而数据量越来越大的今天,数据处理的解释与可重复其实对于整体可重复性来说就成了关键一环。这是可复算性研究(reproducible research)的时代背景。
背景
- 并非所有结果都可以重复
- 当前数据维度增高可被整合入更大的数据集进行重复检验与挖掘
可复算性研究(其实有时也被翻译为可重复性研究)关注的重心在得到数据后的阶段,也就是从得到数据到文章发表的阶段。平时我们能看到的是图,表及文中的数据描述,这些算是数据可视化的部分,产生这些数据描述需要对原始测量数据进行预处理,分析与计算,每一步的处理代码脚本都应该随文章与原始数据一同发表或提交给审稿人进行评估,这样可以最小化数据产生后的问题。
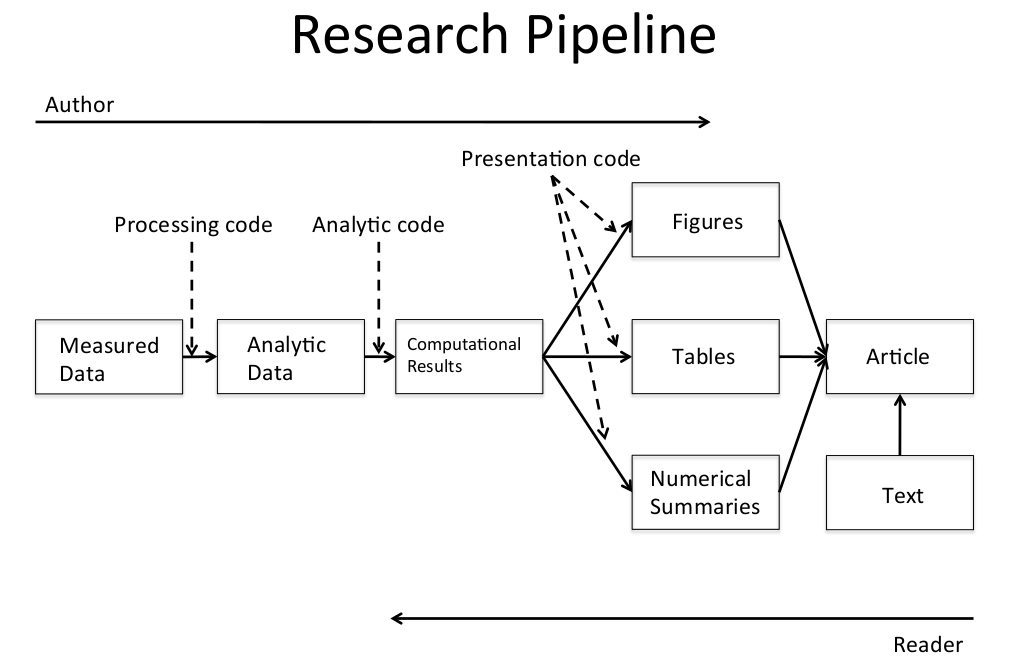
前面谈的是可复算性研究的起源与概念,而真正意义上的实现需要依赖动态报告系统。动态报告是文学编程(Literate programming)的产品,而文学编程思想是Tex语言的开发者高纳德提出的。现在我们把这些概念一个一个串起来。
文学编程不同于结构化编程,简单说就是像写故事那样解释程序以便清晰的描述程序逻辑,具体点就是类似伪代码,但包含真正代码的文本报告,其中的代码可通过编译执行并返回结果。典型代表Sweave,你可以在用Tex写文本的同时混杂R代码段,用特定的符号注明,然后用Sweave处理文本生成PDF报告时你的R代码会同时被执行并可在正文中调用这个结果。
这样的报告也是动态的,例如,我在R代码里用数据A生成一个模型并返回了一个参数,我就可以在正文中调用这个参数名,这样,当我把数据A换成数据B时,我只需修改R代码就可以了,这样一份数据A的报告瞬间就变成数据B的报告了。在谢益辉的Knitr包问世后,这个动态多了另一重含义,那就是真正基于html5的动态交互图形,这个后面会专门有文章去讲。
那么,动态报告与可复算性研究的联系是什么呢?利用动态报告系统,特别是knitr,我可以同时将研究论文与数据处理整合到一个文本里去。什么样的文本呢?越简单越好,不是每个人都喜欢Tex,但5分钟内上手Markdown我认为还是不难的。混合什么样的代码呢?个人觉得R在数据分析上应是不二之选。将这两者结合生成的文本能不能有程序处理呢?有,就是R中的knitr包,它完美支持R与markdown的混合。这样,你只需写一个混合R与Markdown的文本并将R代码标记出来,knit一下就可以处理得到或PDF或word或html的论文,甚至你可以配合pandoc将Rmarkdown文本转化为任意你熟悉的格式。由于Rmd文本中清晰的描述了你的数据处理过程与图片表格的生成过程,作为读者可以很轻松的评价你的工作,进而避免大量对数据处理过程的质疑,如果你投过稿,对这种质疑应该不陌生。这样可复算性研究就可以说利用动态报告实现了,当然,动态报告的功能要远比可复算性研究的要求强大的多。
动态报告
- 可重复性研究的实现系统
- 动态报告的生成需要原始文本(混合数据处理代码的文本如Rmarkdown)与处理引擎(knitr)
- knitr的出现极大程度方便了动态报告的生成
OK,介绍完动态报告再推荐一个IDE:RStudio,目前RStudio对动态报告系统(knitr与pandoc)的支持应该是最好的没有之一。