今年ACS春季会议我做了一个口头报告,提出了“看门人分子”的概念。这大概是我又双叒叕挖坑的一个开端,现在预印本已经放到网上了,这里做下解释。
这里我关注的科学问题来自于污染物暴露研究,如果一个人暴露给一种污染物,那么就存在导致某种健康状态的可能。在暴露组学研究中,污染物暴露通常作为某种疾病的预测变量,也就是有下面的关系:
$$健康 = f(污染物,协变量)$$
然而在代谢组学中,我们会认为健康状态是由代谢物水平变化直接导致的,也就是下面的关系:
$$健康 = g(代谢物)$$
这里没有放协变量是因为很多协变量在分子水平上本就可以被某些代谢物来指示,例如性激素水平大概就能指示性别,此时你把性别放到模型里会造成共线性,降低模型稳健度。
观察这两个等式我们会发现,如果代谢物本身可以体现健康状况,那么污染物也就有可能是通过影响代谢物来影响健康状态。注意,此处代谢物是可以被替换为其他来自人体样本的分子信息的,例如蛋白质、组蛋白、基因甲基化水平等。但本质上是一个环境信息传递到分子生物学信息再传递到健康效应的信息流。考虑上遗传作用也就是:
$$环境暴露/遗传 \rightarrow 内源响应 \rightarrow 健康$$
此时我们会发现,遗传影响与环境影响其实都会体现在生物样本的分子信息里,当这三部分都能被观察到时,我们应该可以从分子水平解释环境或遗传对健康影响的机理。遗传那部分不是我关注的,后面只讨论环境影响,这里放上遗传是为了让这个模型逻辑上通顺些,实际不同健康状态的主导影响也是不一样的。
环境流行病学会关注那些受环境影响更大的疾病,但描述暴露与疾病关系却通常是毒理学家在做,这里经常出现毒理学上证明有影响但流行病学数据看不出来(大多数)或者流行病学看到了影响但毒理学证据不充分(少数)。这里的不一致在我看来主要是因为毒理学所采用的控制实验体系过分简化了环境暴露,很多毒理学上用到的剂量现实生活中很难出现,或者说虽然剂量水平相当,但因为缺乏暴露途径或存在其他拮抗暴露影响的机制。更重要的在于很多时候评价指标如果太过宏观就会不够灵敏,而描述暴露跟健康的数值都可以算相对宏观的指标。
因此,要搞清楚环境究竟如何影响健康,我们最好是直接测量人群样品的分子水平信息,这就是代谢组学跟蛋白质组学还有表观遗传组学在做的事。但人群样本不可能做到随机化,我们不太容易拿到个体水平的环境信息,例如我可以知道A地当天室外空气细颗粒物浓度,但不太容易拿到某个人当天暴露的细颗粒物浓度,最简单就是如果这个人自己在家做饭,那么他的细颗粒物暴露量是远高于室外浓度的。
其实,外在暴露的变动范围其实是远大于内源响应的,室外温度可以从零下几十度到四五十度,但人的体温波动不会特别大。从这个角度出发,体内的代谢物分子可以分成两类,一类是对暴露敏感的用来响应与感知外界变化,另一类则是不敏感的用来维持生命系统。可以预想到,人体代谢平衡或者主要代谢通路更多是不敏感的那一类分子在维持,如果暴露真的造成了健康状态改变,那么肯定是先影响敏感分子然后突破敏感分子的信息传播阈值影响到了不太敏感的主代谢通路。那么,这部分敏感的分子就有必要找出来。
这里我们就会发现一个问题,当进行组学研究时,我们是不预设敏感度的,也就是仪器能测到啥我们就报道啥,但这里就涉及一个统计学多重检验的问题,我们会在完全不敏感的代谢分子上浪费大量的统计功效。毕竟现在错误发现率的控制都是基于检验数的,检验数越多,判断出现差异的要求就越高。例如我去进行污染物A对代谢组影响的研究,结果测到了1000种代谢物,然后要做1000次假设检验才能知道哪种代谢物跟污染物有关,此时就要做错误发现率控制。不过其实从一开始我们就知道不会有太多出现差异的,但这部分知识没法反应到数据分析方法里。
现在常用的一个做法就是降维或聚类,把趋势类似的代谢物组合为一个新的潜在变量,然后去跟污染物进行相关分析。且不论到头来你怎么再把影响回溯到具体的物质,这个思路并不解决我们收集了一大堆无关信息。我的想法就比较简单直接,在进行污染物与代谢物之间分析之前,先对代谢物内部相关性进行分析。在设定的相关性阈值之下,代谢物会形成代谢网络,绝大多数情况你会看到一个主干网络与零星分布的小代谢网络,这里我们把这类代谢物叫做大陆代谢物,但更多的代谢物是独狼或孤岛,根本无法与其他代谢物产生任何联系。此时,生物信息的流动是构建在代谢网络上的,因此我们只关注大陆代谢物。这是一个基于概率的假设,不可否认会丢掉一些有用信息,但却能显著降低研究难度。
从我做的案例来看,常规代谢物检测在一个较高相关性阈值下90%以上的代谢物属于孤岛,这样我们通过区分孤岛与大陆就实现了一次基于信息含量的降维。而面对剩下的代谢物,我们会逐一检查其与暴露物的相关性。可以预见,并非所有代谢物都会与暴露物有关系,这样我们就能筛到直接与暴露物打交道的代谢物。因为这些代谢物一方面跟污染物有联系,另一方面又跟其他代谢物有联系,那么很有可能污染物的信息流的接受者就是他们。换句话说,这些代谢物是污染物影响代谢网络的最前线,所以我给他们起名为看门人(gatekeeper)分子。下面是一个简单的看门人分子示意图:
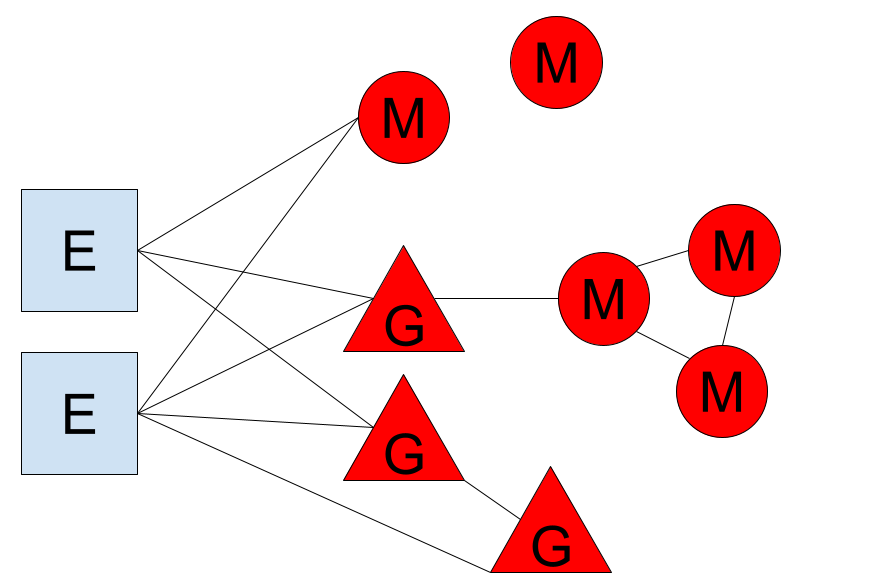
理论上会有两种看门人分子,一种是直接横在暴露物与代谢网络之间的,另一种则是互相为看门人分子。但不论哪一种,看门人分子都应该属于对暴露物比较敏感的,而且在真实数据中,我发现看门人分子可以响应不止一种暴露物。这个发现就说明代谢物层面有可能存在一个相对通用的看门人机制,其实本来环境毒理学就有外源代谢通路的说法,但如果能从小分子层面描述可能更有利于阐明影响机制。
不过看门人分子只处理了环境暴露跟代谢物的关系,我们最开始的那个问题,也就是影响健康的机制还没有讨论,只是把讨论范围缩小到了具体的代谢物上。在我做的案例中,环境暴露无法直接发现跟健康的关系,但当我用这些暴露物的看门人分子来研究与健康的关系时,可以直接观察到看门人分子与健康状态的关系。也就是说,看门人分子要比直接用环境暴露研究健康影响更灵敏。这倒不难理解,毕竟环境影响的测量不确定性本来也比代谢物测量不确定性要高。
其实看门人分子这个概念的本质还是基于网络分析的,基因组里比较流行的WGCNA这个包的核心也是发现网络结构后对每个独立网络结构做svd分解,然后取第一个主成分来代表网络进行下一步分析。不过,看门人模型从一开始就是直接针对具体的代谢物来建模的,通过筛选网络结构来找出有实际意义的代谢物,形成假设方便后续检验。也就是有下面的关系:
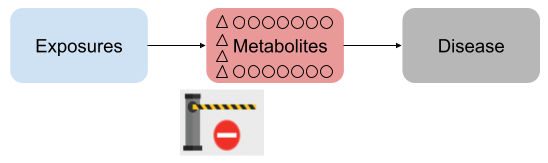
这个分析方法的重点就在于我把代谢组限定到了看门人分子这个子集,这些代谢物可能更适合进行环境影响相关的疾病研究(起码初步的结果是这样)。同时,看门人分子不仅仅可以是小分子代谢物,还可以是蛋白质或其他生命大分子。这样看门人分子实际就成为了可以把各种组学连在一起的概念,而且这部分分子要比其他分子对环境因素更敏感,更可能是健康防护的第一条防线。
关于这个概念我已经做过四次报告了。从反馈上看,做生物信息的把这个方法看成了利用信息量降维的手段;做统计的第一反应是这玩意怎么看着像因果分析;做生命科学的认为这个概念比花里胡哨的分析方法简单,容易设计实验验证;做流行病的则强调一定要把协变量给考虑进去且考虑其在预防医学上的意义,特别要考虑灵敏度问题;做环境的更关心能不能直接给出一个基于人体代谢物的看门人分子数据库。我之所以费劲写这篇介绍就是因为预印本被很多不同背景的人改的一言难尽,所以干脆拿母语把核心概念重写出来算了。
从我个人角度跟能力,其他方向我做不了但我乐意与之交流,学科间应该有更多的互动而不是互相睥睨。不过,这个概念倒是有可能跟我之前所说的反应组学进行联动。当前的网络结构是利用相关性来构建的,但基于质量差的反应组也可以用来构建网络,而且解释性可能更好些。其实我并不喜欢炒作概念,主要原因是很多新概念只是构建了学科间的壁垒,但看门人分子这个隐喻却有利于学科间的融合,唯一的问题就是当前研究人员是否乐意打破学科壁垒了。
ps. 我本来起的名字是守门员(goalkeeper),至于为啥改成看门人,那又是个关于政治正确的故事,不提也罢。