1979年,英国乐队快乐小分队(Joy Division)发行了自己的首张唱片《Unknown Pleasuers》,这张专辑发行两周内就卖了5000份,但问题是……印了10000份。然而,当乐队的单曲《Transmission》发布后,这张后朋克唱片很快销售一空。作为一个乐盲,我是没搞懂这歌的意思(好像对收音机很不满)。整个70年代不断衰落的英国社会催生了朋克运动,青少年们对现实极度不满,采取了一些很极端的表现形式来抒发感情。有意思的是这个专辑在2017年又重新流行了,倒不是因为社会衰落,而是那个设计极为特殊的封面。

这里说的封面流行是指在数据可视化领域里,其实它本就很流行……在流行文化里。很多人用这个类似波谱的图来指征一种波动、起伏的感受,恰恰应和《Unknown Pleasuers》中那种迷茫而强烈的情感,同时封面设计师又开放了版权,所以我们可以看到其在很多场景中的再现。例如 3D 打印版、服装版、电影版等。甚至有人制作了一个网站来用鼠标生成类似风格的图。不过当我看这个图时是觉得很有问题的:坐标轴是啥?线的间隔是固定的吗?有什么意义?这图怎么做出来的?
冤有头债有主,《科学美国人》曾经对这张封面的源头进行过探索,封面设计师 Peter Saville 是从 1977 年出版的《The Cambridge Encyclopaedia of Astronomy》上面一副关于脉冲星 CP1919 所发出的脉冲波叠加图(不是山峰,也不是波浪)上获取灵感的,但这灵感实质上就是把颜色做了反转还去掉了坐标轴。不过这就说明源头是这本书吗?不,顺着这本书,有人可以追溯到1971年1月刊的《科学美国人》,而1974年《Graphis diagrams: The graphic visualization of abstract data》 上也出现了这幅图。
那么《科学美国人》又是哪里搞到这幅图的呢?事实上1971年的文章之所以要用这幅图,是因为要介绍脉冲星这个上世纪60年代的重大发现,而这个发现的确切时间是1967年,也就是说这个图的出生日期就在1967年与1971年之间。然后我们就找到了 Harold D. Craft, Jr. 在康奈尔大学的博士论文《Radio Observations of the Pulse Profiles and Dispersion Measures of Twelve Pulsars》,到这个时候真正的源头才出现。
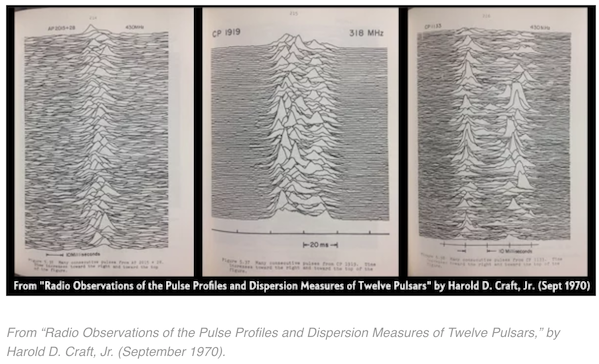
当《科学美国人》联系到 Harold D. Craft, Jr. 时,他顺道也说了下这幅图背后的故事。刚开始在脉冲星在剑桥被发现后,他所在的团队就意识到自己其实拥有当时世界上最好的测量脉冲星的设备,也就是电子设备。然后,从测量结果上他们很快就发现脉冲星的脉冲存在一些漂移,也就是大脉冲里有小脉冲,这个结果发表在《自然》上。但他们觉得需要一个更直观的方式来观察这些脉冲的模式,然后就做了一些叠加图,很快就发现这种图并不满意,前后的遮挡太过严重。作为一个程序员,遮挡问题其实就是一个漂移问题,所以他操起键盘做出了一个漂移版,这样当峰强度足够时才会出现遮挡,而这类峰正是我们想看的模式。不过不要高估那个年代的技术,他还得再找人用印度墨水(其实就是中国墨汁)重新勾描一遍才能清晰的放到博士论文里。不过他显然不是流行文化爱好者,因为直到他同事有天闲逛时发现后高速他他才发现自己的图这么流行,然后他毫不犹豫的买了下来这个专辑与海报:
it’s my image, and I ought to have a copy of it.
我能想象很多人要考虑版权问题了,说实话我也没搞清楚,不过看起来创作者并不在意,而封面设计者也不在意,也许正是不在意促进了某些文化的流行。好了,前世就这样了,那么今生呢?
这事要从7月份说起,twitter 上突然出了这么一张图
Peak time for sports and leisure #dataviz. About time for a joyplot; might do a write-up on them. #rstats code at https://t.co/Q2AgW068Wa pic.twitter.com/SVT6pkB2hB
— Henrik Lindberg (@hnrklndbrg) 2017年7月8日
由于 @hnrklndbrg 给出了 R 源码,一时间大家都开始纷纷回复转发,做出了自己的版本。当然 joyplot 的名字也伴随这条推文开始走红。据说 是 Jenny Bryan 首先提出的这个名字并联系到了上面所说的快乐小分队的专辑封面。
跟专辑还有脉冲星就没关,这个图在增加了坐标轴后的突然流行其实跟最近在可视化里要求展示大量原始数据的需求不谋而合。我们现在考虑这样一个场景,有十组数据,每组1000个数值,如果进行比较,用什么来可视化?
group1 <- cbind(rnorm(1000),1)
group2 <- cbind(rbeta(1000,2,8),2)
group3 <- cbind(runif(1000,min = -1,max = 1),3)
group4 <- cbind(c(rep(1,500),rep(-1,500)),4)
group5 <- cbind(c(rnorm(500,1),rnorm(500,-1)),5)
data <- rbind.data.frame(group1,group2,group3,group4,group5)可能最简单的就是条形图了吧,用条形长度表示均值,然后用标准误或标准差表示变异程度。这里需要说明的是这种作图方法如果倒退到快乐小分队那个年代是很有必要的,因为那个年代作图不能太过复杂,毕竟有时还要描边,属于纯体力活。在这种大环境下你是可以用统计量例如均值来表示数据整体的,甚至 Edward Tufte 都提出了类似奥卡姆剃刀原则的数据墨水比来表示数据的展示要尽量简洁。
但是抽象程度越高,细节信息丢失就越严重,如果我们仅用均值来展示上面的数据会是下面这样:
library(tidyverse)
data %>%
group_by(V2) %>%
summarise(mean = mean(V1)) %>%
ungroup() %>%
ggplot(aes(x=V2, y=mean)) +
geom_bar(stat = 'identity')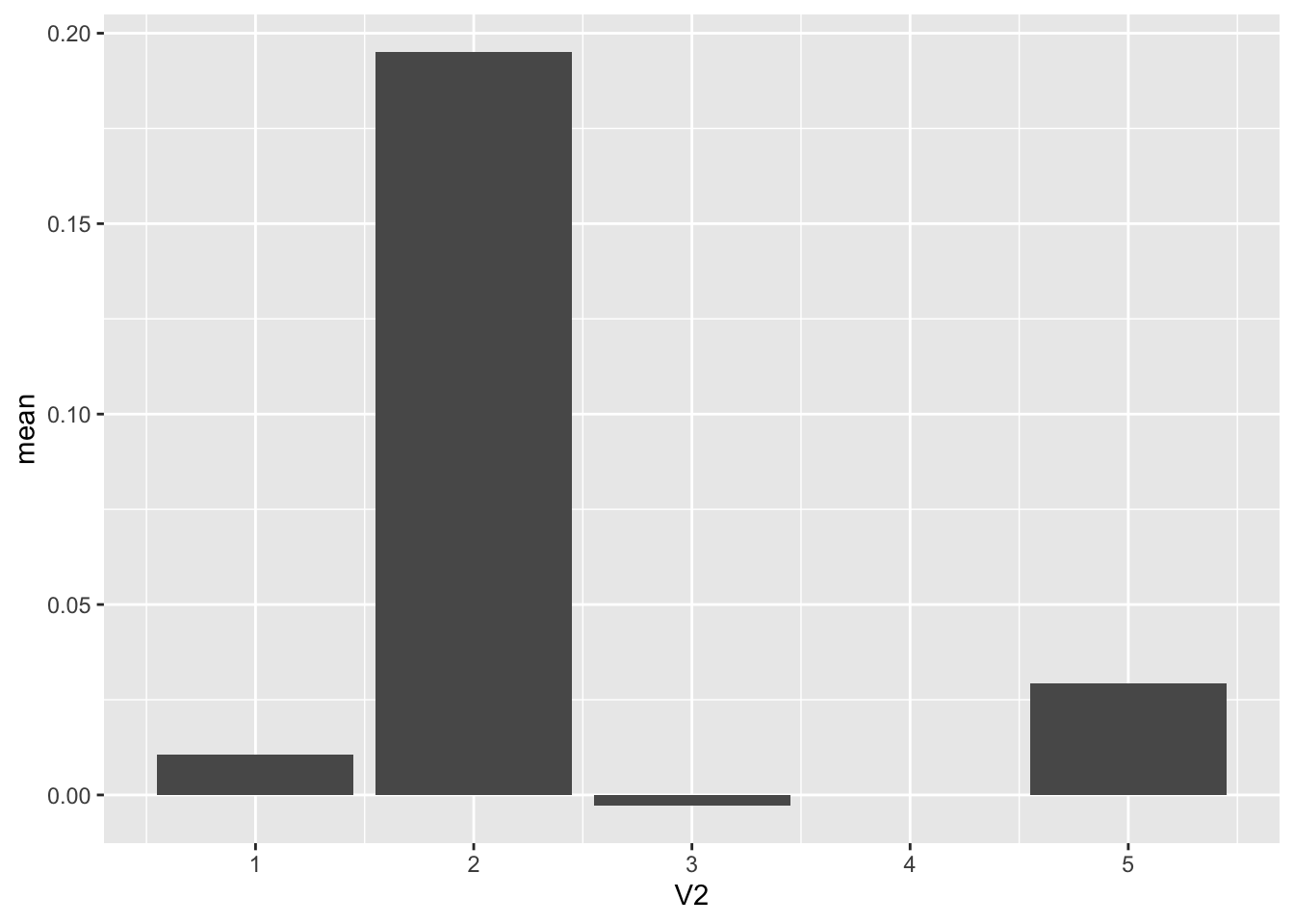
简洁是有了,数据细节几乎完全丢失。当前的趋势是尽可能少对数据做假设,所以要尽可能多的展示细节。那么有人可能就说我用盒式图行不行?
data %>%
ggplot(aes(x=factor(V2), y=V1)) +
geom_boxplot()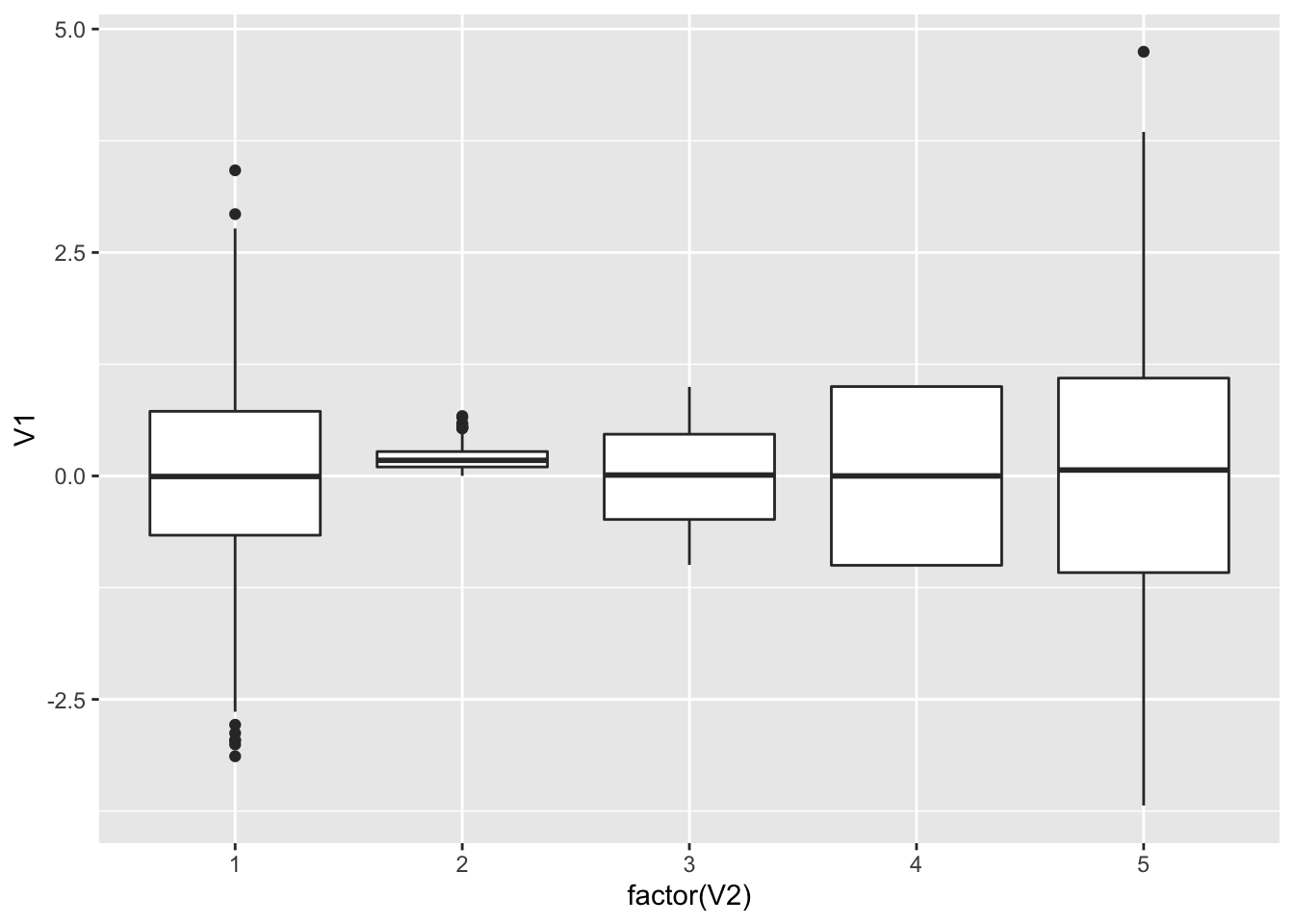
只能说好了一点,因为虽然我们现在有了分位数,但其分布还是看不出来。那么此时有人就说我用提琴图怎么样?毕竟前两天 xkcd 还画了这个图。
data %>%
ggplot(aes(x=factor(V2), y=V1)) +
geom_violin()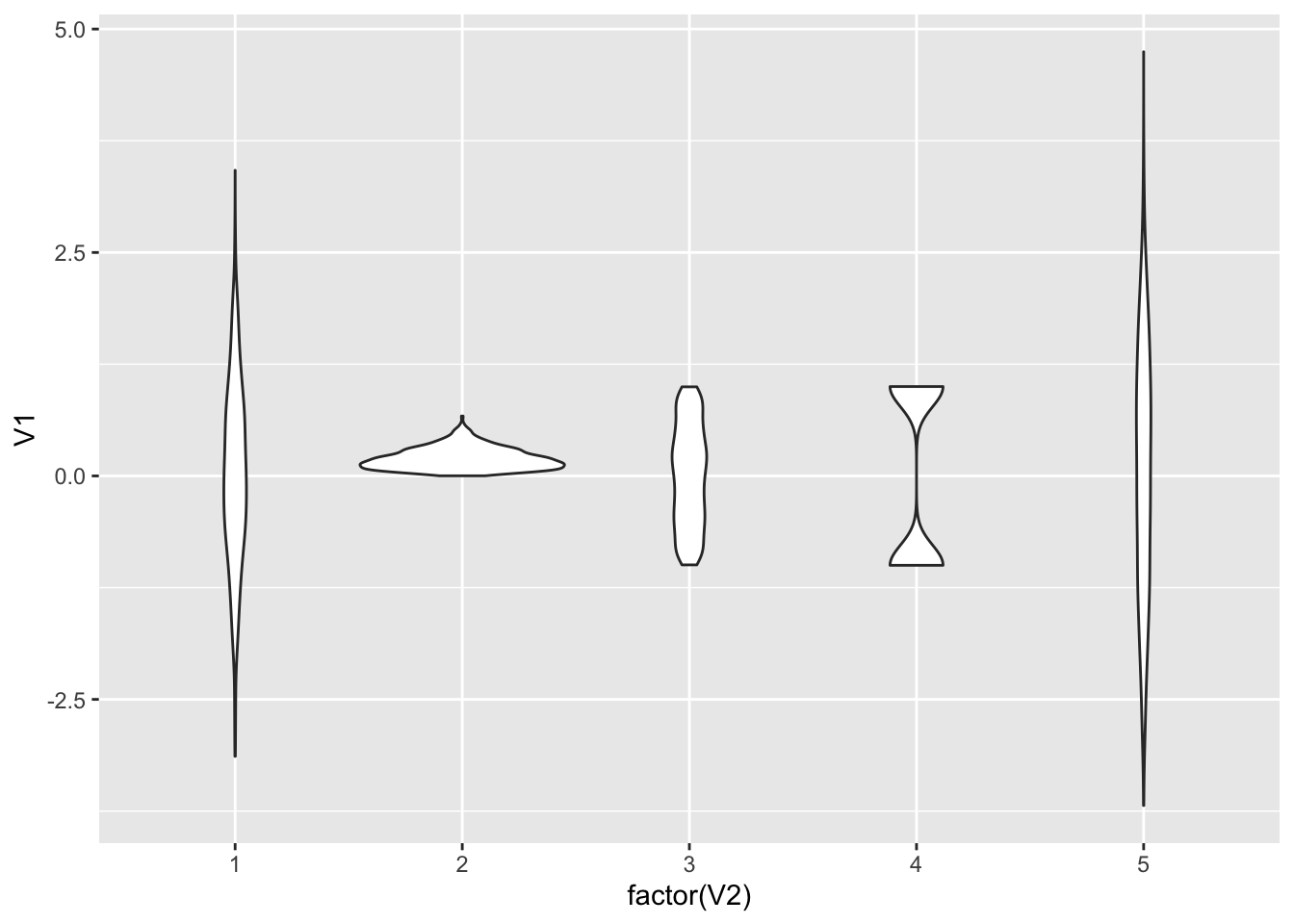
我只能说已经有点意思了,因为数据本身的特点正在展示出来。其实我们也可以直接用抖动散点图来展示。
data %>%
ggplot(aes(x=factor(V2), y=V1)) +
geom_jitter()
不过这里的问题是点在1000这个量级还好,如果多了就只能通过设置颜色透明度来展示了。但 joyplot 却十分适合这个场景:
library(ggridges)
data %>%
ggplot(aes(y=factor(V2), x=V1)) +
geom_density_ridges()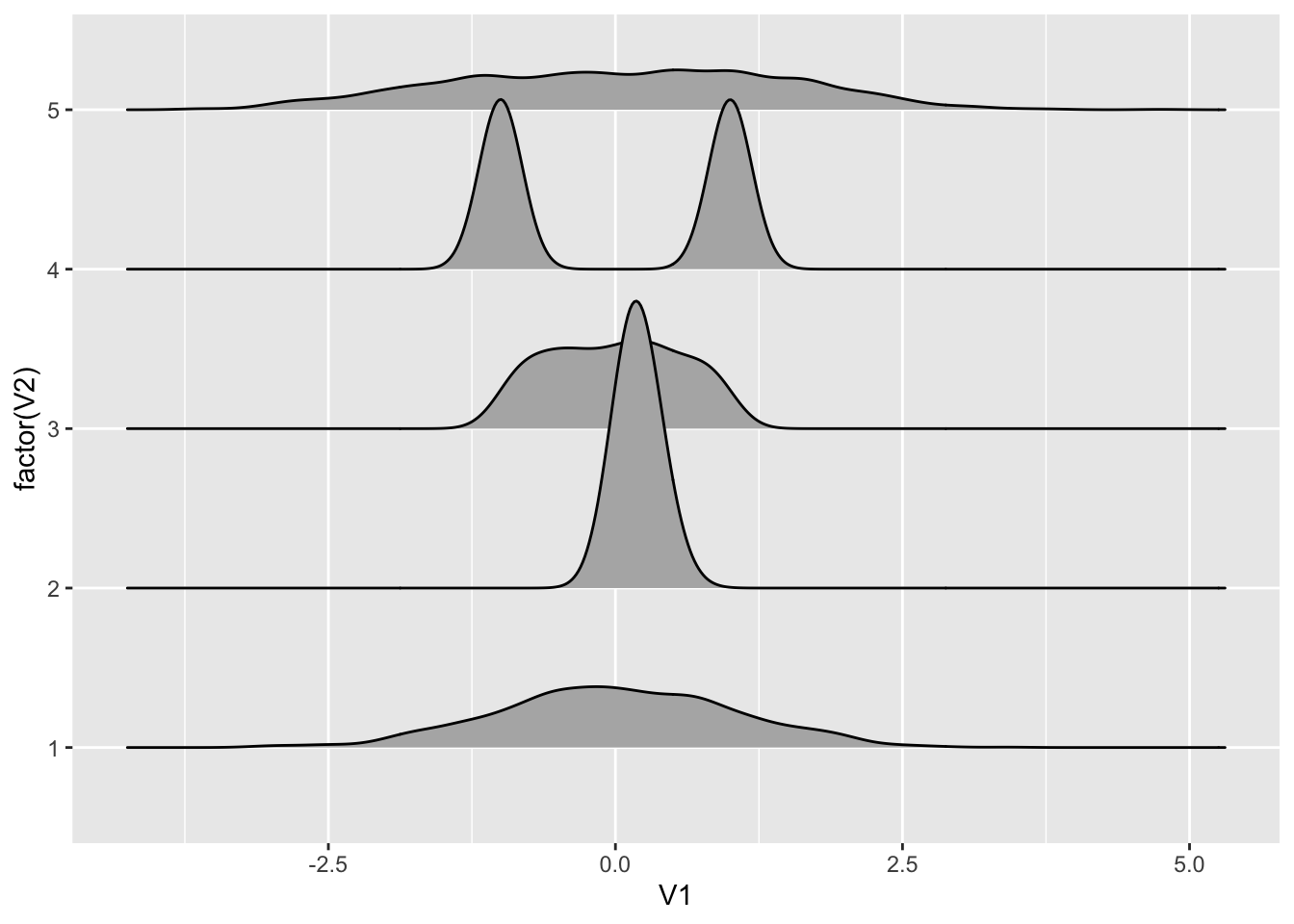
你可以把 joyplot 看成提琴图砍掉一半的样子,但因为有共同基线,所以视觉上比较起来特别方便。你甚至可以用类似直方图的模式来展示分布:
data %>%
ggplot(aes(y=factor(V2), x=V1),height = ..density..) +
geom_density_ridges(stat = 'binline')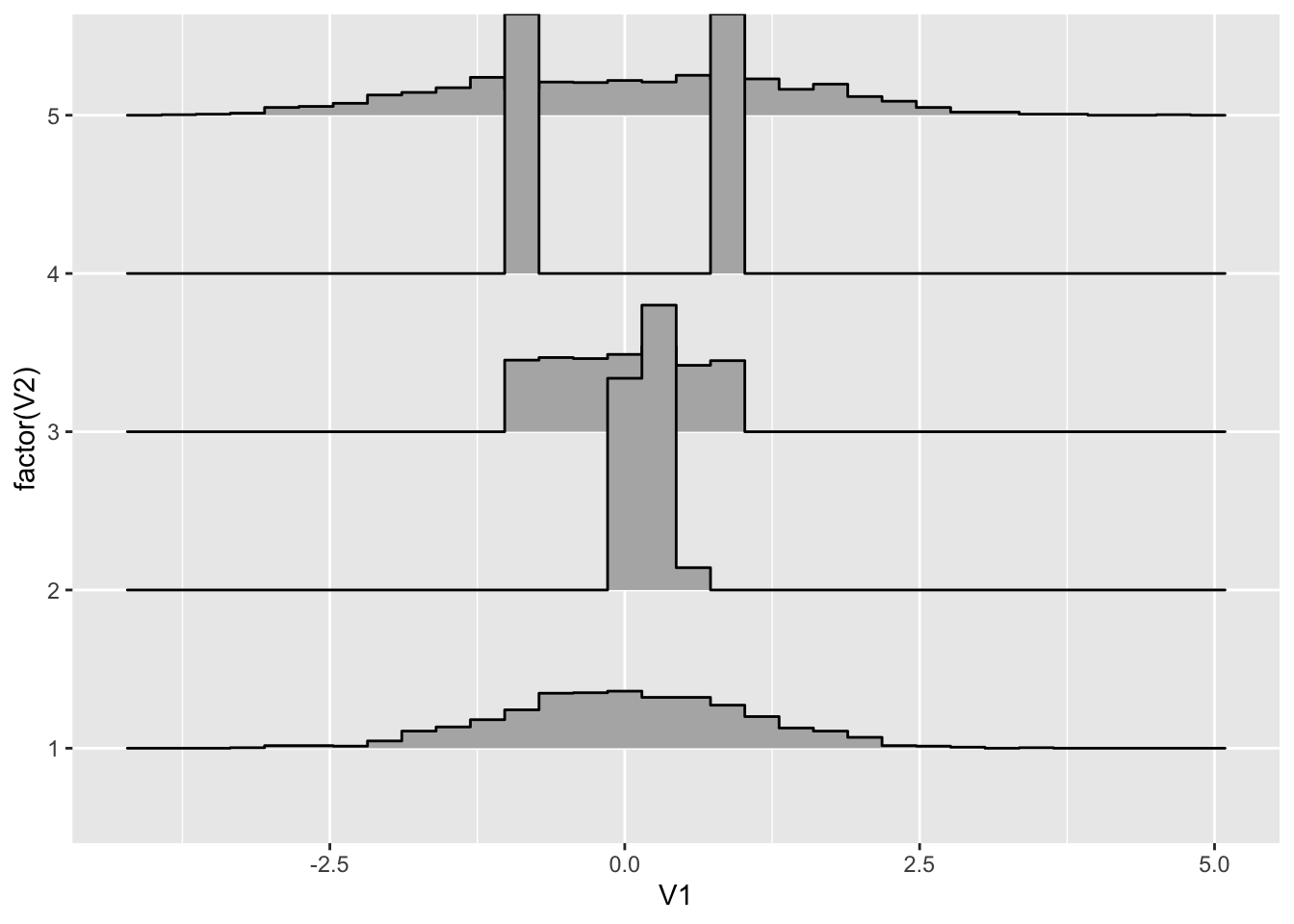
也就是说 joyplot 在展示原始数据状态时属于比较直观的,犹如重山叠嶂,不论是对比峰值还是对比特定数值上概率密度都很简单。
故事还没完,你也注意到了,现在 joyplot 又改名了。新的英文名叫做 ridgeline,中文名暂时就叫叠嶂图吧。原因还是出在快乐小分队上,快乐小分队其实是纳粹集中营里提供性服务的犹太妇女团体,而这个乐队起名的时候就是用的这个典故,这样的黑历史在西方世界乃至全世界都是不愿意提及的,所以很快可以画叠嶂图的 ggjoy 包退休,功能完全一致的 ggridges 闪亮登场。
这就是叠嶂图的前世今生了,前前世比较黑暗,前世是流行文化,今生则是可视化领域的新贵。可能还是有人觉得这个图没啥特殊的,我这里用真实数据来展示下其作用:
library(tidypvals)
aj1 = anti_join(head2015,chavalarias2016)
aj2 = anti_join(chavalarias2016,head2015)
sj1 = semi_join(head2015,chavalarias2016)
allp = rbind(aj1,aj2,sj1)
allp = rbind(allp,brodeur2016)
allp %>%
filter(!is.na(field)) %>%
ggplot(aes(y=field, x=pvalue)) +
geom_density_ridges() + xlim(0,0.25)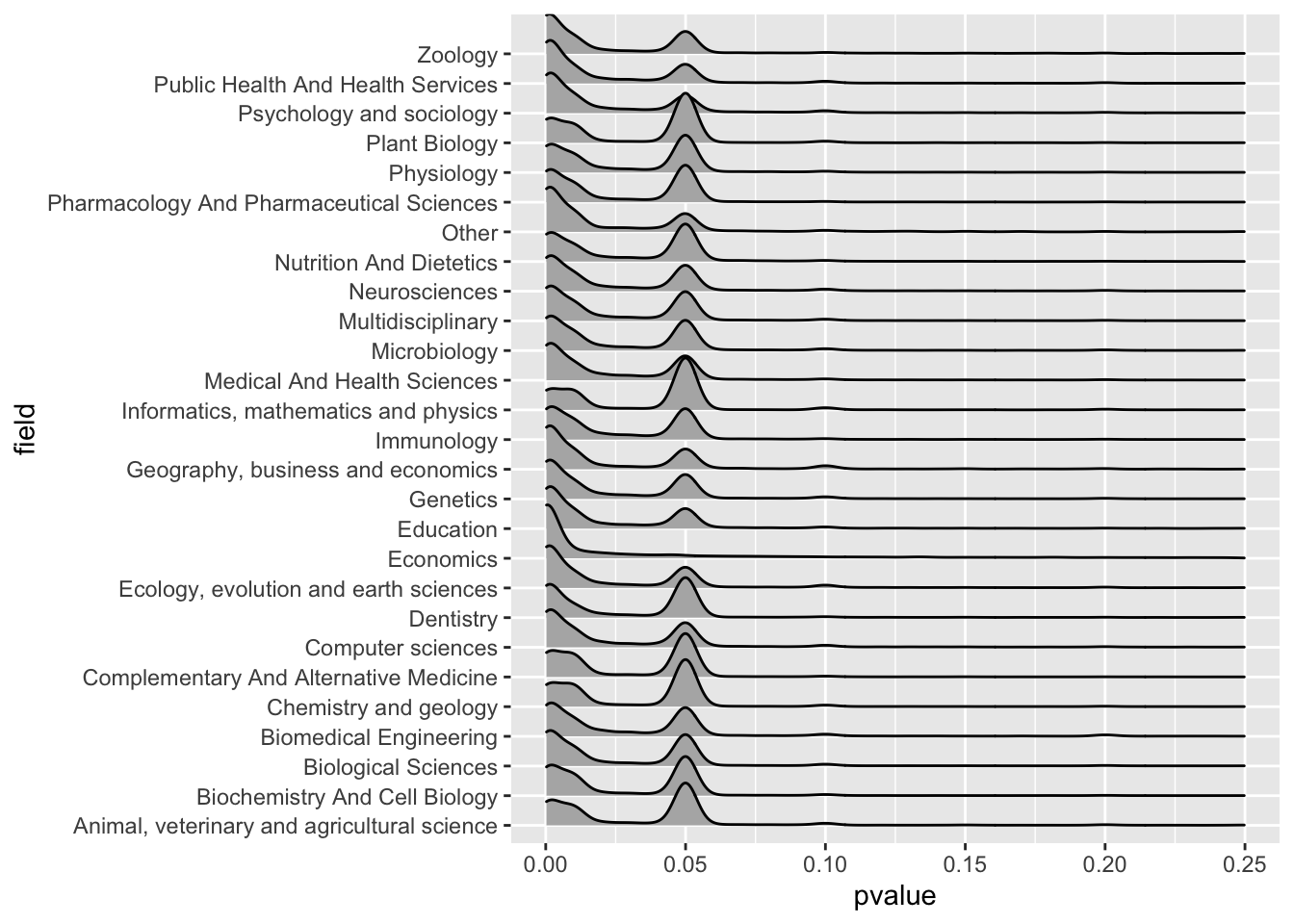
这组数据收集了348414份期刊论文里的3623355个p值,横跨28个学科,现在我问你:哪个学科最有可能在p值上造假或者有发表歧视?你又有没有更好的可视化方法呢?我写这篇文章的目的又是什么呢?