如果说对机器学习或统计学习里最常见的示例数据集进行排序,那么鸢尾花数据集一定排的上号,而且不同于事后诸葛的泰坦尼克生还者数据,这个数据集理论上是可以拿来做预测的。设想某个清晨,你漫步花园并驻足于一朵鸢尾花前,然后你掏出尺子,测量了花萼长度、花萼宽度、花瓣长度跟花瓣宽度后静默片刻,淡淡的说到:“果然又是个维吉尼亚鸢尾。”留下一堆路人甲风中凌乱。
但其实你是做不到的,新西兰统计学家Thomas Lumley最近发表了一篇文章认为,这个数据集其实是Fisher或Anderson拿来想让读者做线性判别或无监督聚类的,而在真实的野外环境中,花从来都不是一个良好的种属判断条件而是探索一个假设的论据。。
现在我们来看看当年究竟是为什么发布这个数据集。Anderson于1936年在《Annals of the Missouri Botanical Garden》上 发表了一篇题为《The Species Problem in Iris》的论文,不得不说我很少读到80年陈酿的论文,特别是这种用52页长篇大论讨论一个种属分类的,还没有摘要。
文章第二章开头就给出了野外判断鸢尾花种属的判据:

从里面我们可以看到,三种鸢尾花的基本判据其实是种子,至于花瓣也可以用。但作者也明确提出,由于非常容易枯萎,对花的测量数据用在分类上并不可靠,甚至良好的保存手段都没有。

然而,作者通过5年的观察研究认为Iris versicolor 跟 Iris virginica 各自种类内部其实变化很大,但本质上还是不一样,作者就用两个英格兰小村庄作为对比,一个在砂石地上,另一个在石灰岩上,其建筑风格也许差不多,但建材不一样,所以无论如何都不一样。但随后作者提出,导致这一现象的原因很有可能是因为其中有一种是二倍体,所以形态上虽然像,但就不是一个种,“A simple hypothesis immediately sugguested itself”。为了说明这一点,Iris setosa登场了,因为这一类分布比较靠北,个头比较小,所以很有可能Iris versicolor是Iris setosa跟Iris virginica的杂合体。为了验证这个假设,作者依赖染色体个数的测量与花瓣花萼等数据,推测Iris versicolor与Iris virginica的亲缘关系要近于其与Iris setosa的距离,两者距离大概1:2。也就是说,在原始文献中,花的测量数据并不是用来分类而是用来计算三个物种间亲缘关系的。
其实Fisher在公布这个数据集时也说的很明确,这些测量数据就是来说明Iris versicolor是Iris virginica与Iris setosa的中间类型,拿来实际分类不靠谱。虽然Fisher自己就是拿这些数据搞了一个线性判别分析。而线性判别分析的实质是认为花的测量数据是来自于不同的分布,通过计算分布参数来进行区别。说的更像人话一点就是我对四个测量值进行一种线性变换,目的是让这种线性变化可以很好的区别三个分类。既然是线性变换最终还是会得到一个预测值,衡量三个分类这个预测值之间的距离就可以进行其关系的推测。结果自然是确认了1:2这个比例,而且后续的研究也在16sRNA上确认了这个发现。
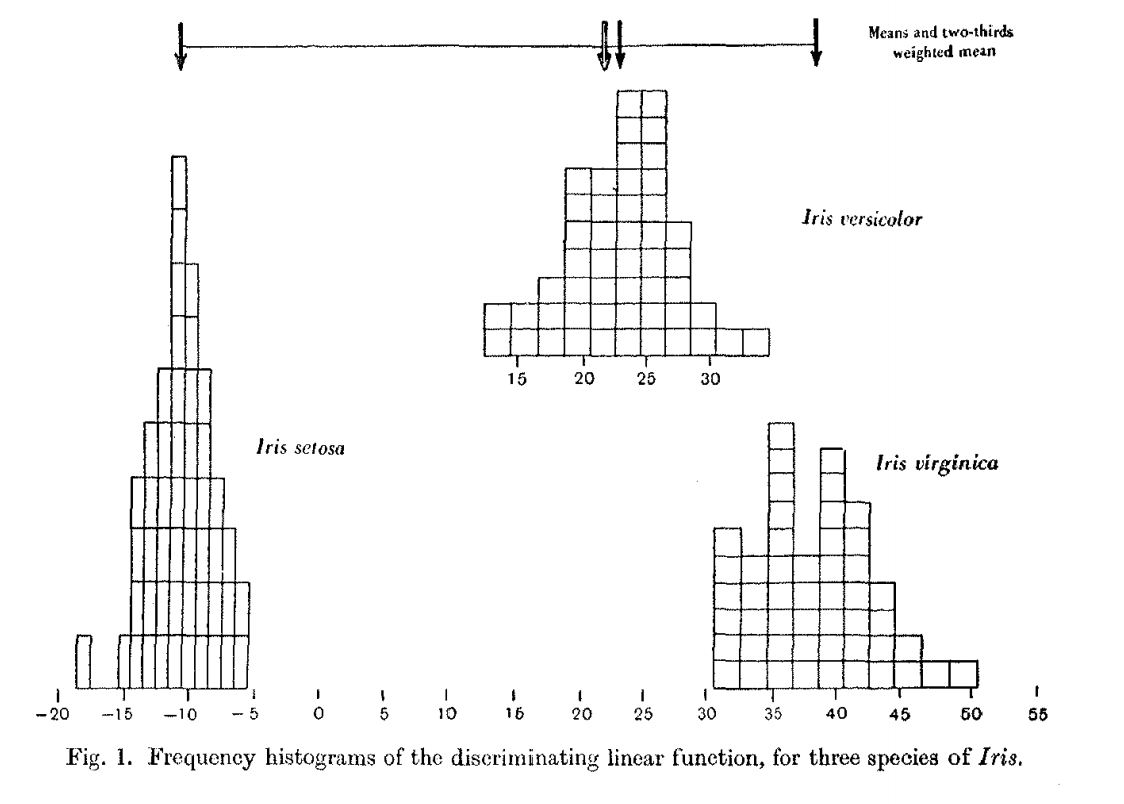
其实从这个数据集的故事是我们可以清晰感觉到的不是一个统计学过程而是科研过程。从观察到提出假说,然后通过数据分析给出证据,最后通过后续的研究不断证明结论,从已知走向未知。而当今的很多研究,你很难找到假设检验的影子,更多偏重的是流程化科研,用更尖端的技术得到更准确的测量,然后甩给统计学家处理,缺少了最初的"insight"。或者说,相对专业的领域分工让科学家自己也变得工具化,缺少研究方法,特别是数据处理方法与实际问题的原理层互动从而将数据分析黑箱化与实用化,这不妨碍实际问题的解决,但会少很多发现的乐趣。
当然,寻找insight可能是未来人工智能可以做的,但愿这一天晚点到来。