之前写过一篇最小二乘法,为神马不是差的绝对值,当时讨论时对最小一乘的基本思想不太了解,只知道不好寻优。后来想想,数值分析里没有解析解的方程多如牛毛也能用一些方法逼近最优值,想来求解也不困难,本来这一页也就翻过去了。However,最近在统计之都上看到了一篇介绍统计学思想的文章,顿时感觉醍醐灌顶,对回归问题也有了新的认识,摘要如下:
-
统计是一种总结的学问,也就是用少量信息反应大量信息的知识
-
给定一组数让你用一个数描述,最大的矛盾就在于这个数如何处理与原有数据不一致的矛盾,毕竟会丢失信息
-
这个过程可以分解为选定描述差异算法与最小化这个差异两步,最后给出的数要具有这两重代表含义
-
选用众数(modes)描述事实上是一个最小零乘问题,也就是二元描述,要么对,要么错
-
选用中位数(medians)描述事实上是一个最小一乘问题
-
选用平均值(means)描述事实上是一个最小二乘问题
详细的内容不再赘述,文章通俗易懂,这里要处理的是问题时为什么最小一乘的解是中位数?这一点在文中一笔带过并没有解释,不知道是不是因为这个问题弱爆了,反正我想了半天才搞明白,本文就是对这个思考过程的整理:
从最小二乘入手
因为我对最小二乘比较熟,那么我首先要考虑为什么平均值是最小二乘的解,答案呼之欲出。最小二乘法的表示方式可直接求导,结果就是平均值,换句话讲,最小二乘法得到的回归线是要经过均值点的,下面我用一个例子来说明这个问题
library(UsingR)
data(galton)
lm1 <- lm(galton$child ~ galton$parent)
newGalton <- data.frame(parent = rep(NA, 1e+06), child = rep(NA, 1e+06))
newGalton$parent <- rnorm(1e+06, mean = mean(galton$parent), sd = sd(galton$parent))
newGalton$child <- lm1$coeff[1] + lm1$coeff[2] * newGalton$parent + rnorm(1e+06, sd = sd(lm1$residuals))
smoothScatter(newGalton$parent, newGalton$child)
sampleLm <- vector(100, mode = "list")
for (i in 1:100) {
sampleGalton <- newGalton[sample(1:1e+06, size = 50, replace = F), ]
sampleLm[[i]] <- lm(sampleGalton$child ~ sampleGalton$parent)
}
for (i in 1:100) {
abline(sampleLm[[i]], lwd = 3, lty = 2)
}
abline(lm1, col = "red", lwd = 3)
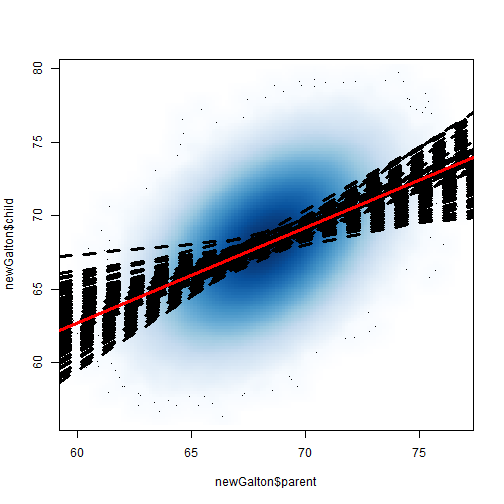
注释我就不写了,这是C站数据分析课讲解最小二乘的一个例子,当我们用预先回归出的模型随机生成一组数据,然后从里面反复重采样100次,每一次得到一个线性模型,把所有的模型叠加,最后我们看到的图形最为稳健的部分就是平均值所在地。也就是说,最小二乘法的内在含义就是平均值回归,用均值代表整体。同时你会发现,这个解是唯一不变的,因为均值的求法不会得到两个答案。那么从这里出发能不能解决最小一乘的问题呢?先别急,先看一个答案不唯一的表示法。
回顾最小零乘
最小零乘的本质就是找一个数,跟数据中一致就是0,不一致就是1。从数据集的角度看就是找到一个数,使一致的1累计最少,那答案脱口而出:众数。但你应该很快就反应过来了,众数可能不唯一,所以最小零乘给出的答案不唯一,这对回归而言是灾难性的,因为不唯一的描述是不确定不可重复的。OK,在这个基础上,我们可以讨论最小一乘了。
最小一乘与中位数
从刚才的论述中,我希望读者可以明白两件事
-
回归事实上就是一种简化版的总结,算法是用来支持总结的,不必须唯一
-
为了求解方便,我们倾向于使用表述上分歧小且求解方法稳定的算法,平均值或者说最小二乘很符合这一点
那么为什么要提最小一乘呢?都用最小二乘不就完了吗?注意第一点,最小二乘仅仅是一种算法,他没有太多的特殊性,也并不完美,一个异常值就足以毁掉一组看似不错的数据,想想统计学里著名的安斯库姆四重奏,这个算法算不上稳健的。而反观中位数却往往可以规避异常值问题,那么这又是如何实现的呢?
我们从最基础的问题开始构建,考虑5个点1,2,3,4,10, 如果找一个数代表这三个数你会选择什么?众数的话哪个都可以,均值的话是4,中位数是3。其实哪个都可以,但如果有个实际背景的话我想更多人会觉得3差不多,有点代表性,毕竟对于10有点信心不足。先不管这些,让我们想想最小一乘算法是如何实现的,如果这5个数分布在一个数轴上,找一个数使其绝对值最小怎么找?很简单分下组,最大值与最小值一组,第二大与第二小一组,以此类推。如果存在一个数满足到所有数的距离绝对值最小,那么它一定位于每一组之间,因为只有这样才能保证其到两端距离最短,这样到了最中间的那个数就直接考虑去中间那个数,这样距离为零,差的绝对值的和自然最小了。同时我们会发现如果我们两个两个的加入数,这个算法也是稳定的,也就是可以推广,这样异常值不过是其中的一组数,求解的结果对特定一组数据并不敏感,这就保证了稳健性。OK,那这个数是什么呢?没错,中位数。
说到这里你会觉得少点什么,没错,这好像只对奇数管用,偶数个数怎么办?其实在处理偶数时,我们最早学到的中位数概念是一种误导,没必要取均值。放到数轴上看,在最中央的两个数之前的任何一个数都可以最为最小一乘的解,那么这就是开始我说到的问题了,寻优结果不唯一。目前可以使用的最小一乘算法应该都无法规避这个问题,但相比众数,起码可以给出一个范围了,同时我们也看到,这个解法具备一定的可编程性,所以也可以拿来用。不过正如谢益辉在其硕士论文中所提到的,对中位数敏感一样可以造成回归上信息的缺失,所以也请把最小一乘看成一个普通青年的算法,最小二乘也是,至于众数……最好别用。而这些在建模上都是要反复考虑才能去选择的,不要盲目追新。
OK,如果你能理解数轴,最小一乘的算法及其与中位数的关系对你已经不陌生了,如何实现的问题就交给学统计的来做吧,我们只需要知道调用相关函数就可以了。如果你觉得最小一乘是不是只是一个求解特例,那恭喜你,直觉不错,最小一乘是分位数回归的特例,后面还有很多新知识。
从特殊到一般,从一般到很一般,这个过程的乐趣不是一般的特殊。